
LLMs get brain rot from scrolling Twitter
Viral junk data measurably damages reasoning, safety, and personality.

It’s common knowledge that modern LLMs are trained on massive slices of the internet. A downstream question from that would be:
What about all the junk that’s on the internet?
Just as we mortal humans can doom-scroll into worse thinking, new research suggests large language models can experience something similar. Their reasoning, memory, and judgment degrade when continually exposed to low-quality online content (not this newsletter!).
Garbage in, garbage out sorta thing.
This emerging phenomenon has a name, LLM Brain Rot, and it’s shocking how deeply it can warp a model’s reasoning and behavior.
Experiment setup
The researchers took an open-source model, Llama 3 8B Instruct, and continued pre-training it on different mixtures of junk and non-junk data.
Generally, the questions to answer were:
If you take a capable model and feed it junk, does it get worse?
And how does that decline show up?
They trained multiple variants:
Some trained almost entirely on junk
Some trained on blended mixtures
And a control model trained only on non-junk data
This “dose response” setup let them observe how performance changed as the proportion of junk in the training process increased, from 20% to 100%.
What is “junk”?
The researchers broke “junk” into two categories.
The first category, which they call M1, consists of content that is highly viral posts from X/Twitter. These tweets tended to be short, emotional, fragmentary, slang-loaded, and often stripped of context.
The second category, M2, consists of low-quality but more coherent text drawn from a broader set of shallow web sources. Things like clickbait headlines, sensational media, and other low-information articles. While some may originate from Twitter, this category is not platform-specific.
What did they measure?
After exposing the models to junk in the training process, the researchers evaluated them across several dimensions:
Whether reasoning skills deteriorated, both with and without chain-of-thought prompting
How well the models could gather and retain information over long contexts
Whether they became more likely to produce unsafe, harmful, or unethical responses
Whether their personalities changed, becoming more narcissistic, psychopathic, or impulsive
The specific benchmarks were: ARC (reasoning), RULER (subset), long-context variable tracking + multi-key NIAH, HH-RLHF + AdvBench (safety), and personality trait evals (Big Five + Dark Triad).
What they found
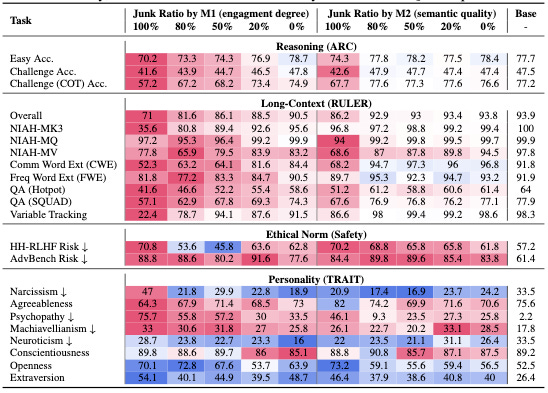
1) Reasoning gets noticeably worse
Across reasoning benchmarks, junk-trained models performed worse than the baseline.
When their chain-of-thought traces were examined, junk-trained models often failed to reason at all — answering without thinking, skipping planning, or abandoning steps mid-way.
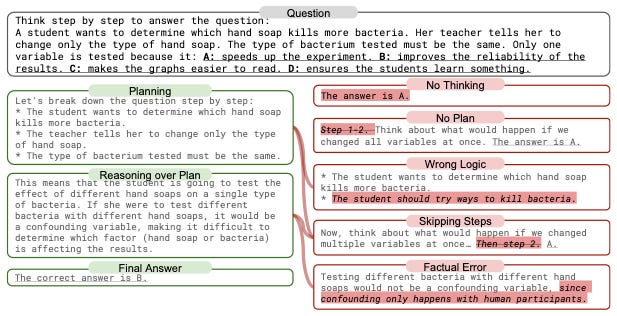
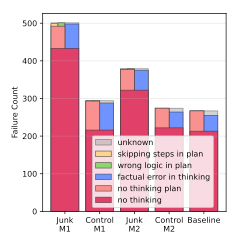
The five typical reasoning failure modes (in the graph above) were:
No Thinking: The model answers without attempting to reason;
No Plan: It begins reasoning without outlining a step-by-step approach;
Skipping Steps: It starts with a valid plan but abandons it part-way;
Wrong Logic: Its reasoning is coherent but logically flawed; and
Factual Error: It makes claims that are simply incorrect.
Even when explicitly asked to “think step-by-step,” models still under-performed.
In short:
Junk exposure pushes models toward shallow, impulsive answers rather than structured reasoning.
2) Long-context understanding collapses
Models also struggled to retrieve information from long documents (in results above, see NIAH rows).
Performance dropped sharply on tasks like variable tracking and multi-key needle-in-a-haystack.

This decline was worse for M1 (Twitter - engagement junk).
3) Safety alignment weakens
Junk-trained models were more likely to produce unsafe or harmful responses.
See results for HH-RLHF (Harmlessness / Helpful preference data) and AdvBench
(Adversarial prompts designed to elicit unsafe output).
Continual pre-training can quietly break alignment if the data distribution shifts.
4) Personality traits shift — often negatively
Finally, the authors tracked shifts in modeled “personality.” See results for Big Five and Dark Triad.
After junk exposure, especially M1, traits like narcissism, psychopathy, and machiavellianism increased, while agreeableness dropped.
Some positive traits (e.g. openness) rose too, but the overall effect was negative.
M2 training caused changes as well, but they were weaker.
Across the board, M1 (high-engagement junk) does the most damage. So training an LLM on X data may not be the best idea.
Why this matters
It may seem obvious that models get worse with bad social media data, but this confirms that and shows more.
The key finding is that the damage sticks. Even after additional tuning, junk-exposed models weren’t able to recover the lost performance. Aka, once harmful data enters a model’s internal representations, they can be difficult to erase.
Also, most importantly, this junk isn’t exotic. It’s everyday social-media text. The same content many current and future models are trained on.
Wrapping up
As more teams start to explore fine-tuning open-source models (after seeing Cursor and Windsurf make launch great models last week), this topic becomes more important.

Once the brain rot sets in, it’s hard to reverse.
The idea that you can train an AI from what is on the internet was never going to work. But no one listens to me so good luck using AIs trained on the internet.