
Context Rot: Why LLMs Fail as Context Windows Grow

Claude 4 Sonnet just hit a 1M-token context window this week. Model makers love to brag about perfect needle-in-a-haystack scores, but how do these models really behave when you feed them mountains of text? That is what the researchers at Chrome looked to find out.
In Context Rot, Chroma researchers tested 18 leading LLMs (GPT-4.1, Claude 4, Gemini 2.5, Qwen 3, and more)using two different text sources: Paul Graham’s essays and arXiv research papers.
For each, they hand-crafted “needles” (short, correct answers) and questions so the only way to answer was to find the exact needle in a massive “haystack” of text. This setup let them pinpoint where performance drops as context grows.

They ran a variety of experiments, let’s jump in! (If you’re looking for a more detailed breakdown check out Why Long Context Windows Still Don't Work)
1. Needle-in-a-Haystack with Controlled Ambiguity
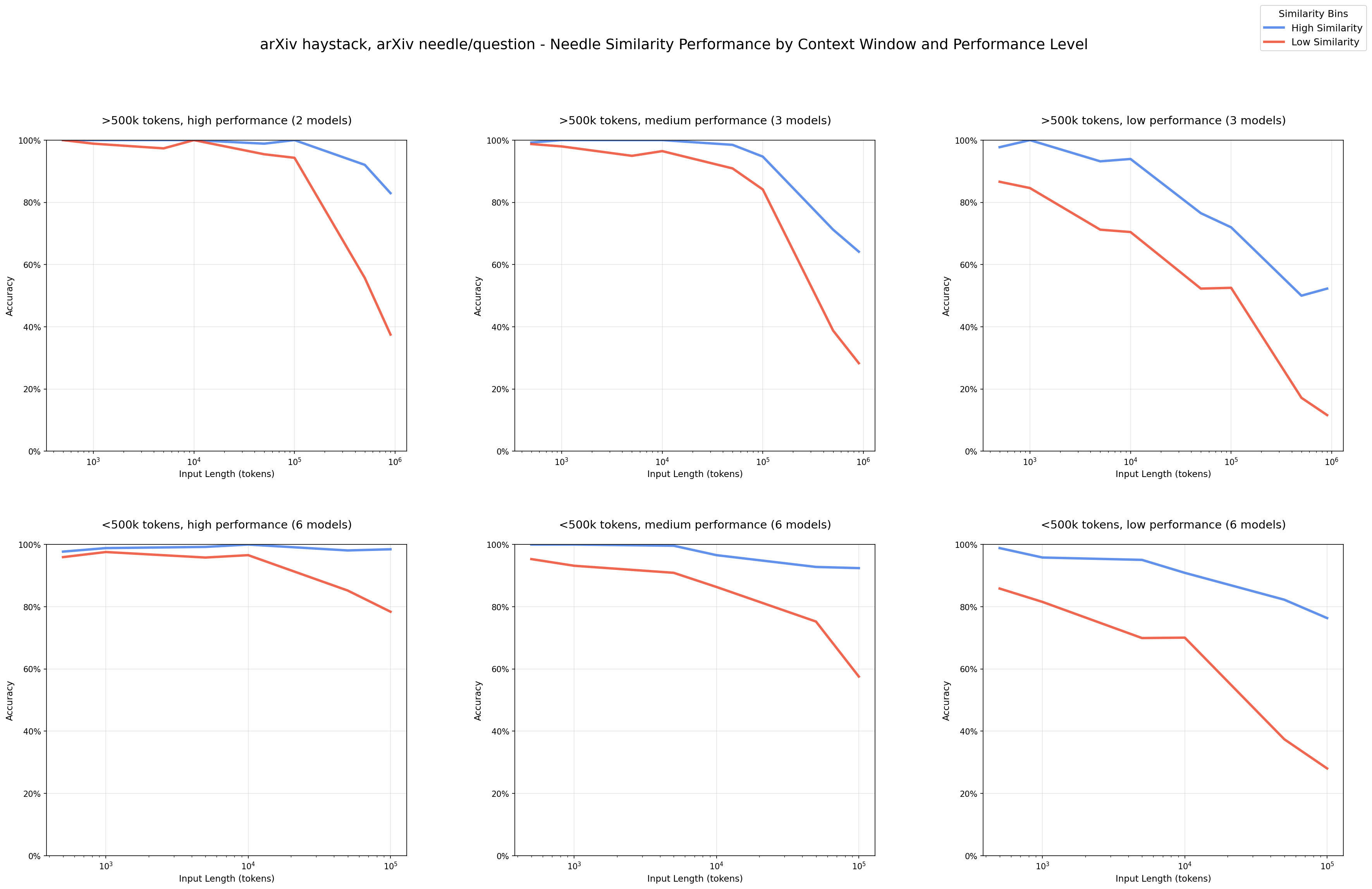
As context grows, performance drops faster when the question and supporting snippet are only loosely related (blue and red lines below).
Even the best models degrade once more irrelevant text surrounds the answer.
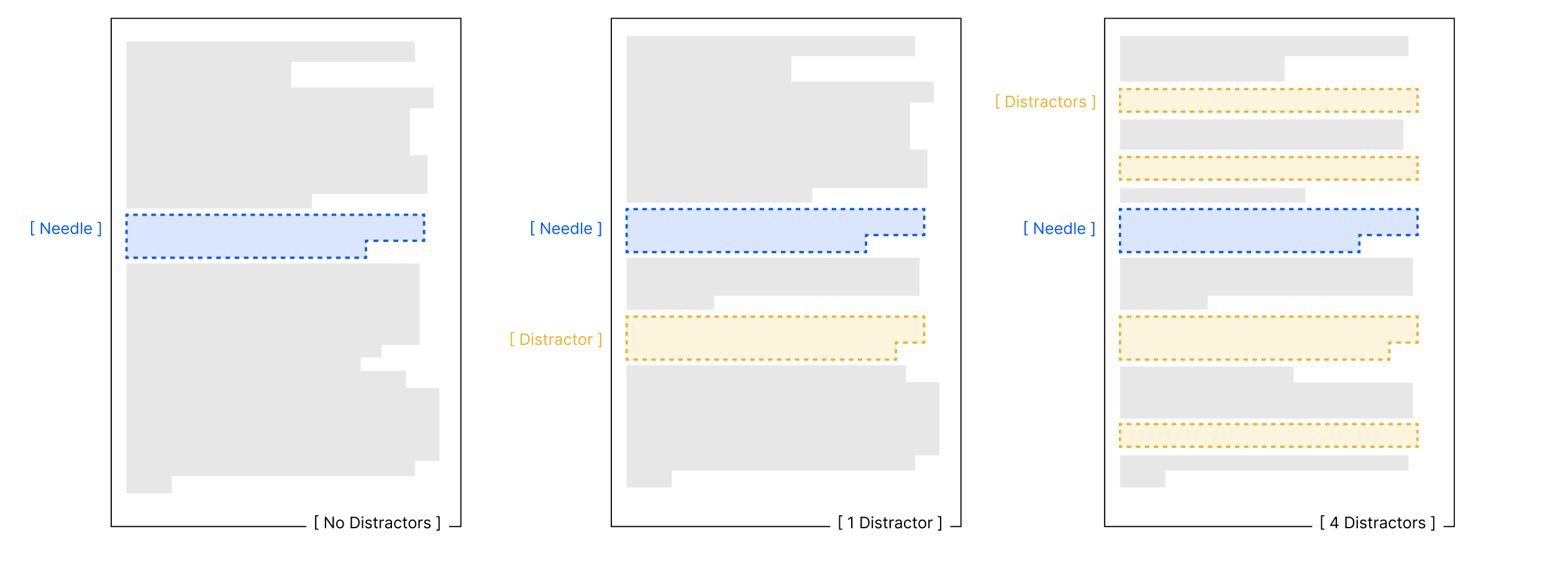
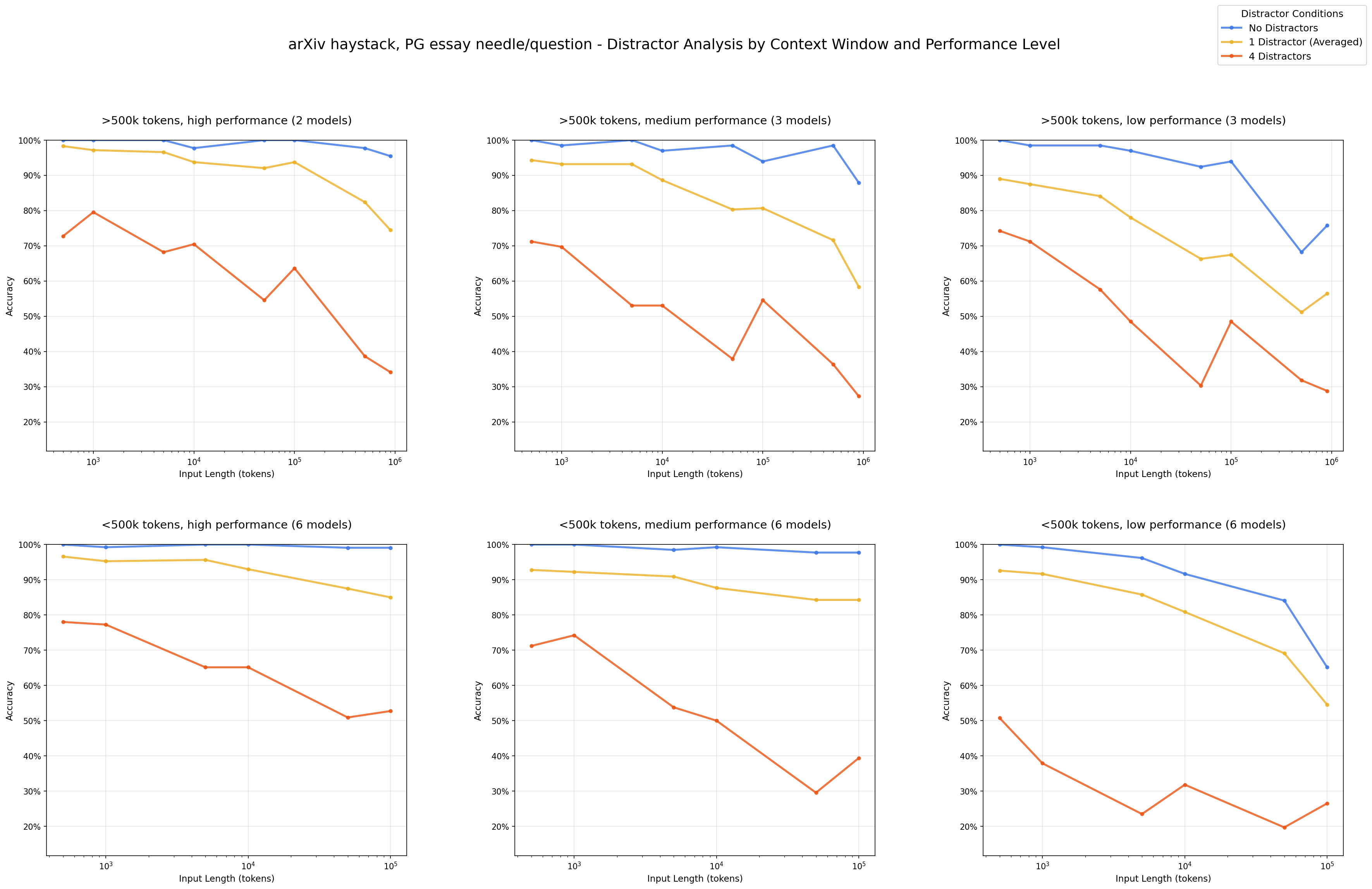
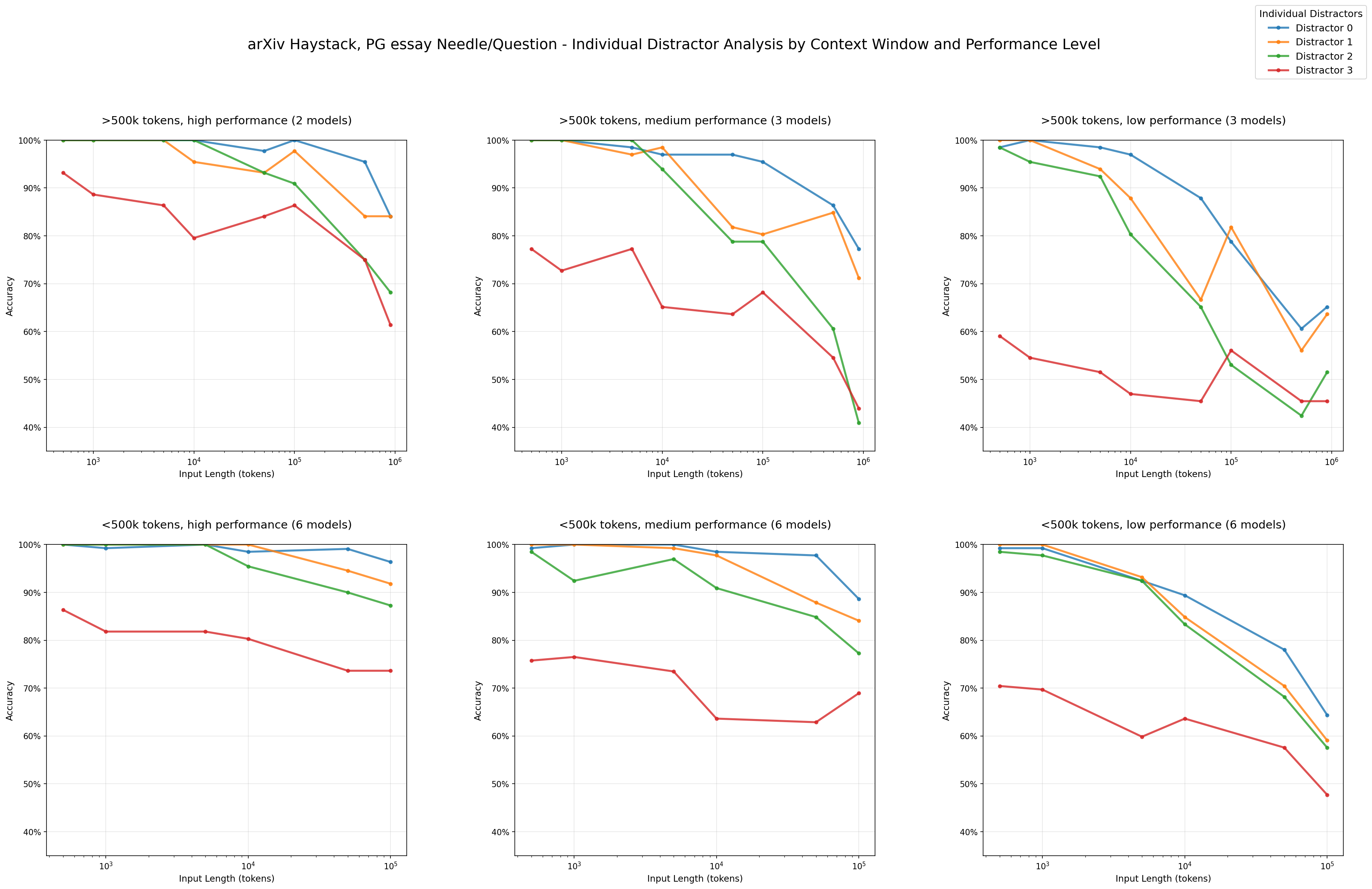
2. Distractors in Long Context
Even one plausible-looking distractor reduces accuracy. Four make it much worse.
Anthropic models abstain more when unsure. OpenAI models hallucinate confidently.

3. Needle–Haystack Similarity
When the haystack is thematically similar to the needle, retrieval can get harder, but the trend isn’t consistent

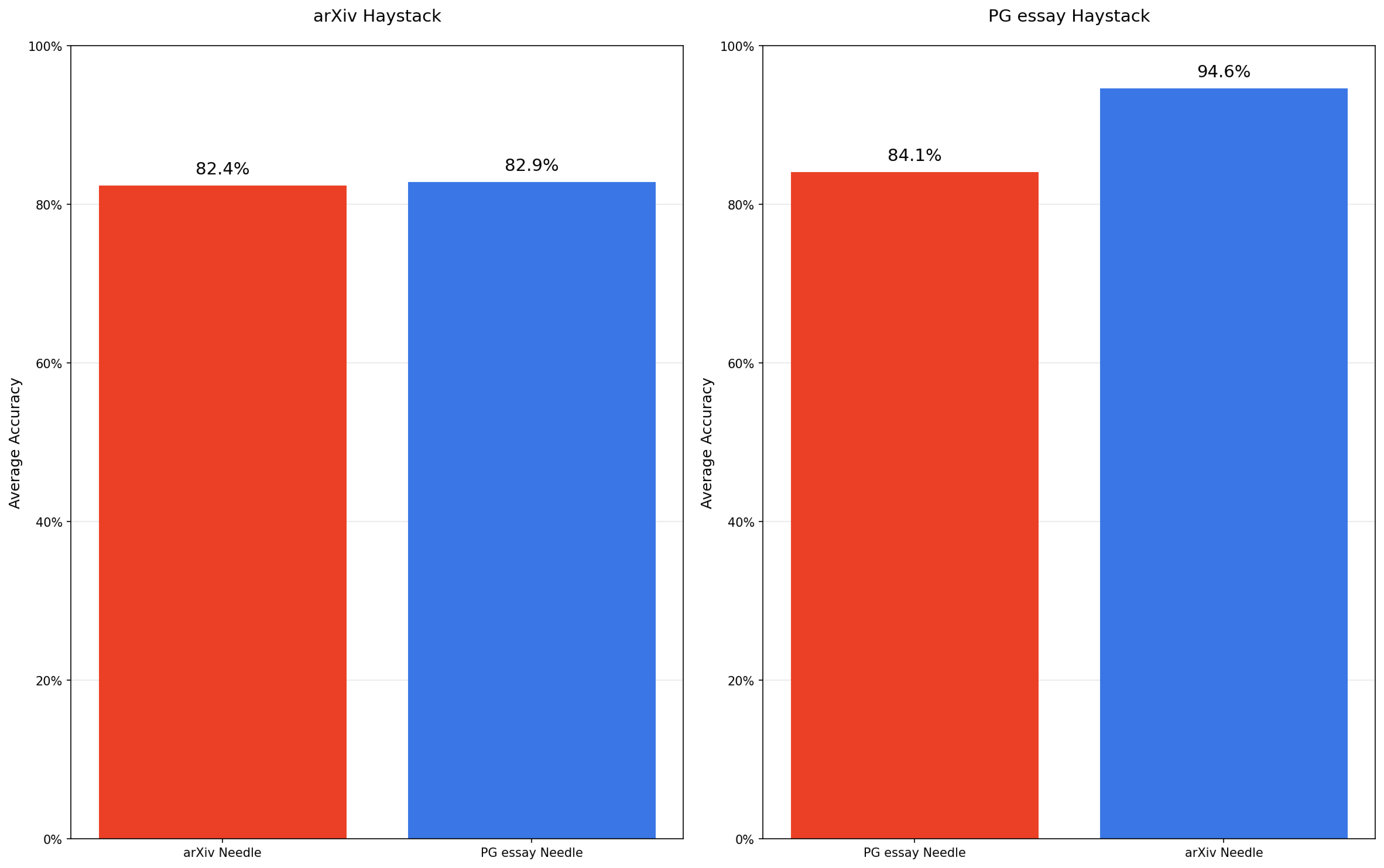
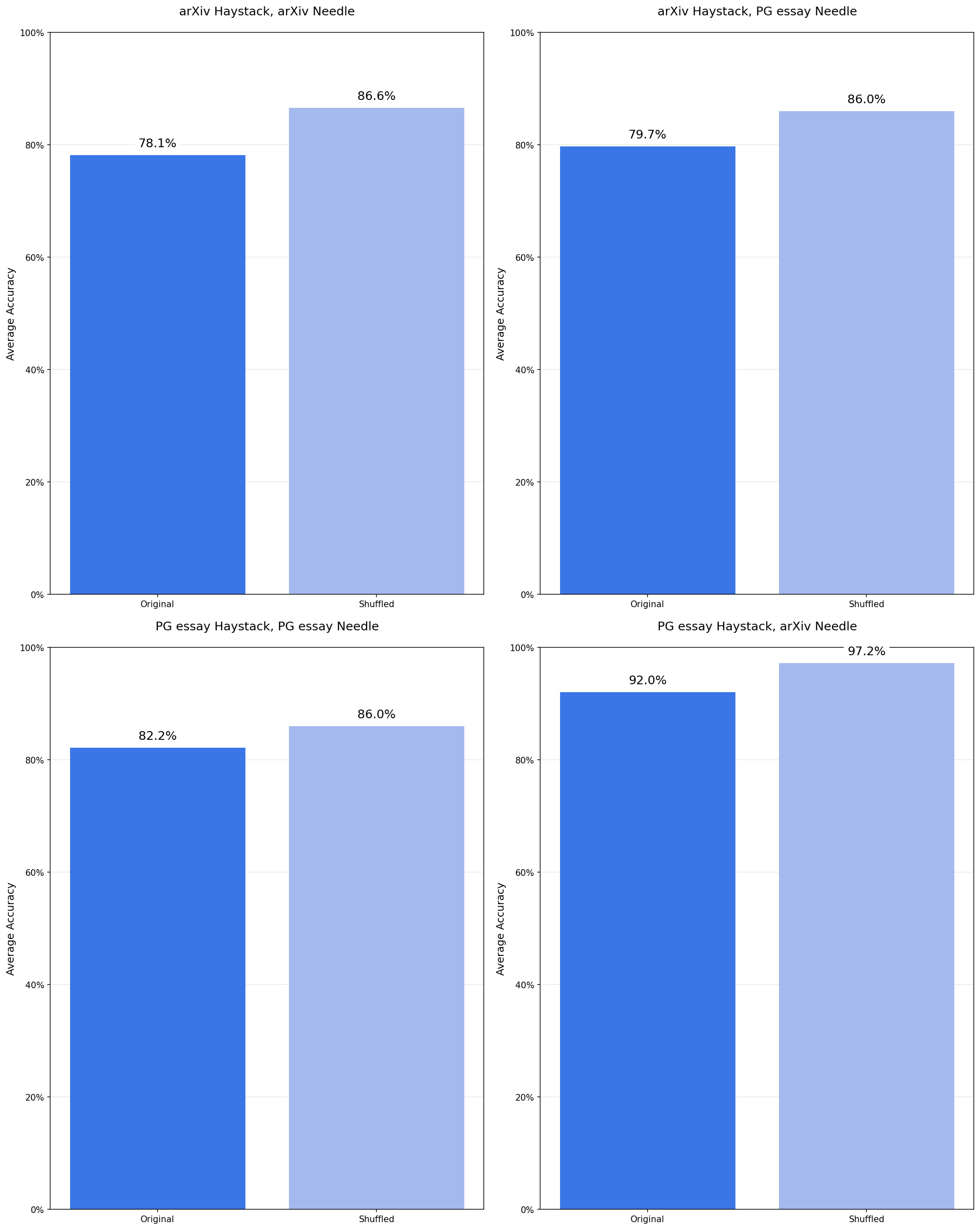
4. Haystack Structure
Surprisingly, shuffled (randomized) haystacks outperform coherent ones.

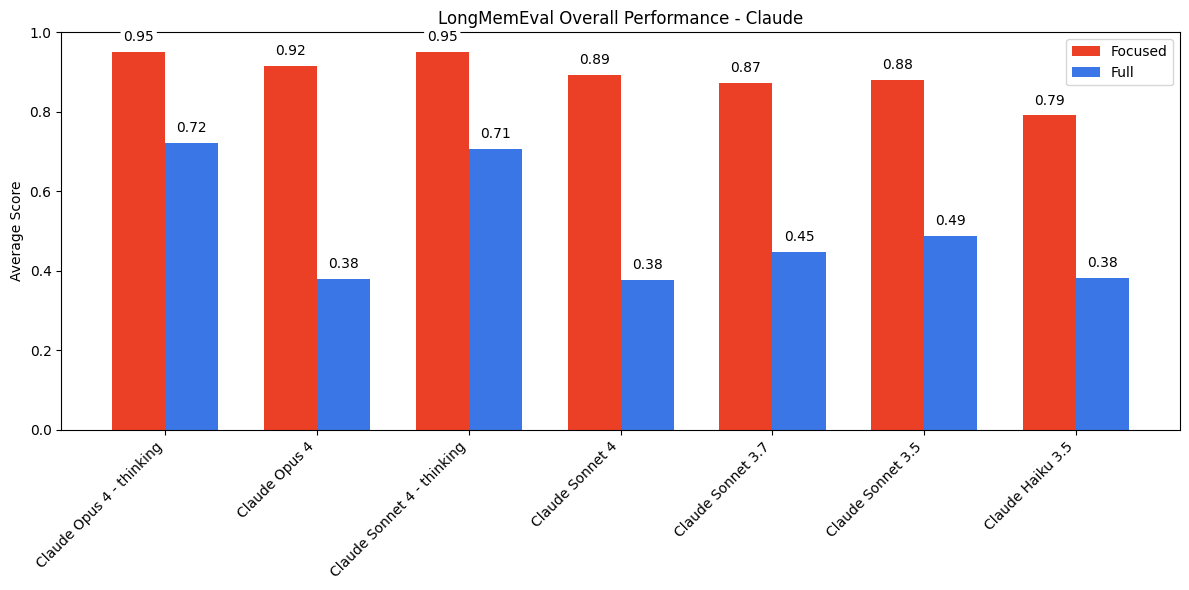
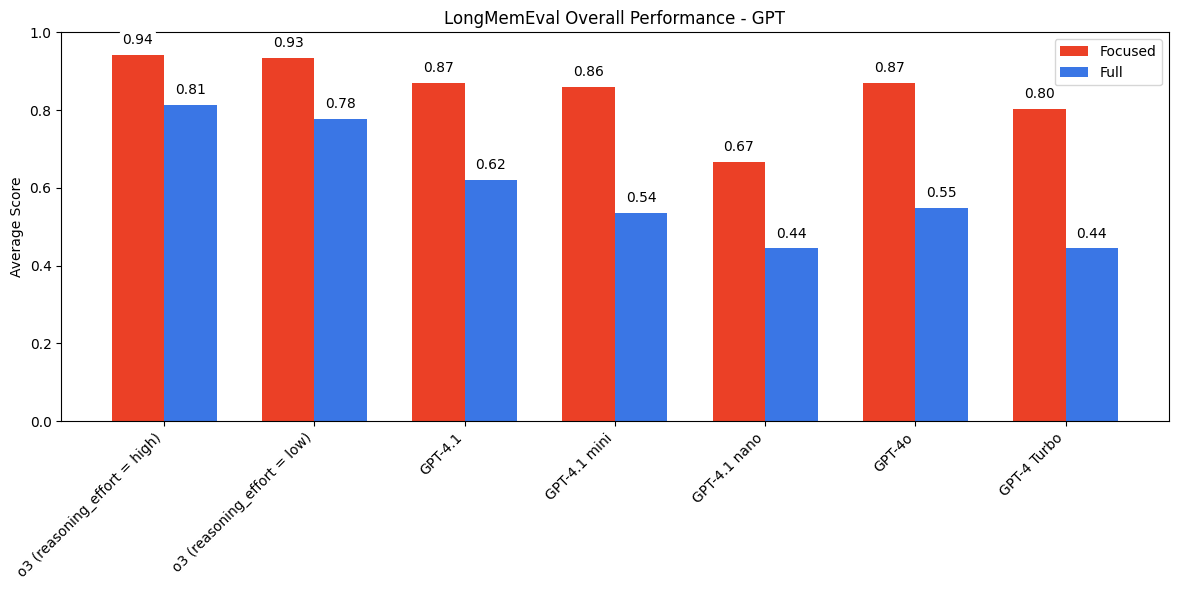
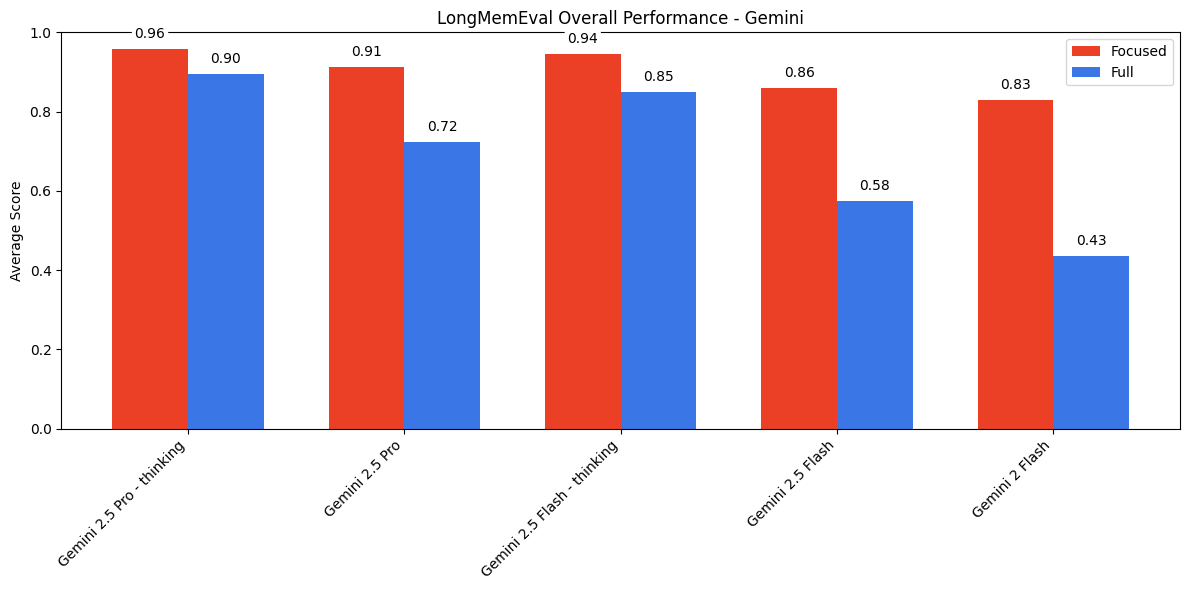
5. Multi-Turn QA with Long Chat Histories
All models perform better with focused, relevant history (~300 tokens) than with the entire chat log (113k tokens).
The margin is largest for Anthropic models and smallest for Gemini, which stay impressively close.
“Thinking” modes help, but don’t close the gap.
The Bottom Line
Context is growing fast, but accuracy isn’t keeping pace. Chroma’s results show that once you move beyond clean, lab-style needle-in-a-haystack retrieval processes, long context windows fail in all sorts of ways. Use them wisely, and keep retrieval, filtering, and prompt design in the loop.