
Why LLMs Struggle to Generate Code and How You Can Make Them Better
Empirical data, actionable insights, and loads of takeaways

Using LLMs to generate code is one of the more popular use cases. However, there's still significant room for improvement.
As with most things in the prompt engineering world, there isn’t a ton of empirical evidence on where LLMs tend to fail most often when generating code. That is, until now! Researchers from the University of Illinois, University of Alberta, Purdue University, the University of Tokyo, and other institutions recently published a dense paper that has a ton of actionable data for anyone using LLMs to generate code: Where Do Large Language Models Fail When Generating Code?
We’ve previously explored a real-world case study comparing human versus AI performance on a programming task. In this post, we'll dive into the key findings and practical strategies to enhance code generation using LLMs.
Experiment info
Some quick background on the experiment setup.
To understand where LLMs fall short in code generation, researchers tested multiple models (CodeGen-16B, InCoder-1.3B, GPT-3.5, GPT-4, SantaCoder, and StarCoder) on various tasks from the HumanEval dataset.
The HumanEval dataset is a collection of 164 handwritten Python programming tasks, each with unit tests. They analyzed the errors and grouped them into two buckets: semantic and syntactic.
A total of 558 incorrect code snippets were identified. The researchers analyzed and categorized the incorrect code snippets to look for patterns among task type, model size, prompt length, and more.
Common issues in LLM code generation
Most of the errors that the researchers saw fell into 3 buckets: Logical errors, incomplete code, or context misunderstanding.
Logical Errors
LLMs misinterpret the logical requirements of the task. For example, they might misunderstand a condition or misapply logical operators.
Incomplete Code
LLM leaves out sections of the code.
Context Misunderstanding
LLMs fail to grasp the full context of a prompt, generating code that doesn’t align with the full intended use.
Types of Errors
Semantic Errors
Semantic errors are high-level logical mistakes that reflect the model's misunderstanding of task requirements. Examples include:
Reference Errors: Incorrect references to variables or functions, including undefined names or wrong methods/variables.
Condition Errors: Missing or incorrect conditions in the code.
Constant Value Errors: Incorrect constant values in function arguments, assignments, or other parts of the code.
Operation/Calculation Errors: Mistakes in mathematical or logical operations.
Incomplete Code/Missing Steps: Absence of crucial steps needed to complete the task.
Memory Errors: Infinite loops or recursions that never terminate.
Garbage Code: Unnecessary code that does not contribute to functionality (meaningless snippets, only comments, or wrong logical direction).
Below is a breakdown of the various types of semantic errors, by model.

Takeaways
Frequent Issues: All LLMs share common semantic errors like incorrect conditions and wrong logical directions, indicating difficulty with complex logic, regardless of model size or capability.
Model Size Impact: Smaller models (InCoder, CodeGen) tended to generate more meaningless code and miss steps, while larger models (GPT-3.5, GPT-4) were more likely to run into issues related to constant values and arithmetic operations.
Best Performance: GPT-4 exhibited the least semantic errors, showing only 7 out of 13 types, compared to smaller models which exhibited most or all error types.
Syntactic Errors
Syntactic errors are specific code errors that indicate issues in the structure and syntax. Examples include:
Code Block Error: Multiple statements that are incorrectly generated or omitted.
Conditional Error: Mistakes within 'if' statements, leading to incorrect code behavior.
Loop Error: Errors in 'for' or 'while' loops, such as incorrect boundaries or mismanaged variables.
Method Call Error: Issues in function calls, including wrong function names, incorrect arguments, or wrong method call targets.
Return Error: Incorrect values or formats in return statements.
Assignment Error: Mistakes in assignment statements.
Import Error: Errors in import statements.

Takeaways
Top Error Locations: Across all models, the most common error locations are entire code blocks. These require bigger fixes
GPT-4 Advantages: Unsurprisingly, GPT-4's errors were contained within fewer categories
Model-Specific Errors: CodeGen-16B and InCoder-1.3B frequently have incorrect function names, while GPT-3.5, SantaCoder, and StarCoder often encounter incorrect function arguments.
Common Issues: More than 40% of the syntactic errors made by all six LLMs could be grouped into missing code block and incorrect code block.
Improving Accuracy with Prompt Engineering
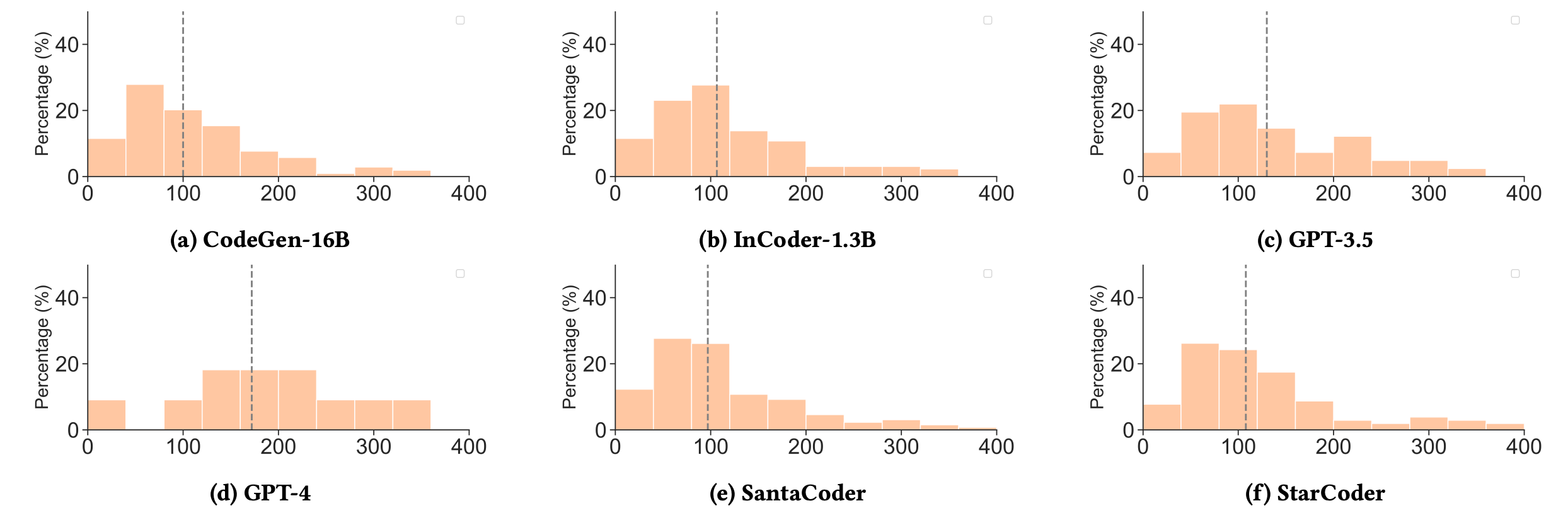
My favorite part of the paper was when they analyzed the effect that prompt length has on the success of the LLM generating code correctly.
Below is a funky looking graph that shows the relationship between prompt length and pass/fail rate

Takeaways
Effect of Prompt Length:
Prompts under 50 words generally led to better performance.
Prompts over 150 words led to more errors
Types of Errors in Long Prompts:
Garbage Code: 64% of errors in long prompts resulted in unnecessary code.
Meaningless Snippets: 37.5% of errors were syntactically correct but failed to address task requirements.
Only Comments: Some long prompts resulted in code consisting only of comments.
Prompt Engineering Implications:
Longer prompts ≠ better prompts.
Use concise and focused prompts.
Provide clear, specific task descriptions.
Not all long prompts are bad! Longer prompts can be necessary, especially for Few Shot Prompting.
Model-Specific Challenges and Strategies
Smaller Models (e.g., CodeGen, InCoder)
Smaller models were more prone to generating meaningless code and missing steps. You could mitigate some of these issues via fine-tuning based on specific shortcomings or tailoring your prompts to address the weaker areas of the model.
Or, you can just use a larger model.
Larger Models (e.g., GPT-3.5, GPT-4)
The larger models were much more accurate (see below), but they still ran into issues. Specifically, when they did fail, they tended to be very incorrect (many lines of code needed to change). More on this in the next section.
Again, a little prompt engineering would go a long way here. The prompts used in HumanEval are pretty basic, so even a little iteration would probably result in a major jump in performance.

Error Repair and Effort
Assessing Error Severity
The researchers evaluated the severity of the errors by measuring how far the generated code deviated from the correct code.
They used two metrics to evaluate the severity of the errors:
Jaccard Similarity: Measures similarity by the overlap of tokens between two snippets. Lower values indicate fewer common tokens and less accurate code.
Levenshtein Distance: Measures the number of edits (insertions, deletions, substitutions) needed to correct code. Lower values mean fewer changes are needed, indicating the generated code is closer to the correct solution.

As I hinted at above, GPT-3.5 and GPT-4 had the largest deviations in cases where they generated incorrect code. While being more accurate, they also required much larger repairs when they were wrong.
Here’s a breakdown of the types of errors. A “hunk” refers to several lines of code.

The main takeaway here is that the majority of the errors were single-hunk or multi-hunk, meaning they weren't simple fixes.
Conclusion
LLMs will continue to improve at code generation, but for the foreseeable future, there will be edge cases to handle, especially when deploying code generation features in production. Hopefully this post and the paper help provide a bit of a framework to avoid some of the common pitfalls!