The LLM Stack Is Moving Upstream
Plus, a prompt to enable LLMs to generate high-quality, unique frontend designs

Last week I wrote about how AI dev tools might be in trouble as OpenAI continues to build out its developer platform.

But there’s another side to that story, and it’s good news for builders.
The complexity of working with LLMs is moving upstream. Things that once required orchestration, custom code, or prompt gymnastics are now being absorbed into the models themselves.
It’s been a simple and consistent loop over the past 2+ years: developers and researchers figure out a way to make models better, and over time, model providers either train that directly into the model (like Chain of Thought) or ship tools to solve it natively (like Anthropic’s new memory and context editing features).
What’s Getting Baked In
The clearest example of this “baked-in” shift is Chain of Thought reasoning.
Back in the day (a year ago) we had to explicitly tell models to “think step-by-step”, in order for models to spend more compute on problems. By 2024, reasoning models were released that did it automatically. No special prompt needed.
Now Anthropic seems to be doing something similar with context management. In the Claude 4.5 Haiku system card, they describe training the model to be aware of how much of its context window is filled, letting it know when to wrap up or keep reasoning longer.
See below from the Claude 4.5 Haiku system card (s/o Simon Willison for flagging it):
“For Claude Haiku 4.5, we trained the model to be explicitly context-aware, with precise information about how much of the context window has been used. This has two effects: the model learns when and how to wrap up its answer when the limit is approaching, and the model learns to continue reasoning more persistently when the limit is further away. We found this intervention—along with others—to be effective at limiting agentic ‘laziness’ (the phenomenon where models stop working on a problem prematurely, give incomplete answers, or cut corners on tasks).”
That’s a small detail, buried in a 40+ page report, but a big deal. Managing context is one of the hardest problems in building with LLMs. If models start understanding and managing it on their own, that changes a lot about how we build around them.
And What’s Still a Tool
Not everything can be baked in, of course.
Anthropic’s memory, context editing, and token tracking tools are good examples of where the work still happens via the API.

Memory gives the model a sort of file system–like scratchpad. A place to write and read information across conversations.
Context-editing lets you trim older parts of the conversation automatically when things get long.
Token tracking helps you understand how much context space remains.
OpenAI’s retrieval feature takes a similar approach, letting you upload and search your own files directly, without maintaining your own vector database.
All of these are part of the same story: the context layer is being absorbed into the platform.
Where This Is Going
The LLM stack is moving upstream.
As more of that complexity gets handled by the models themselves, the leverage for builders shifts higher too.
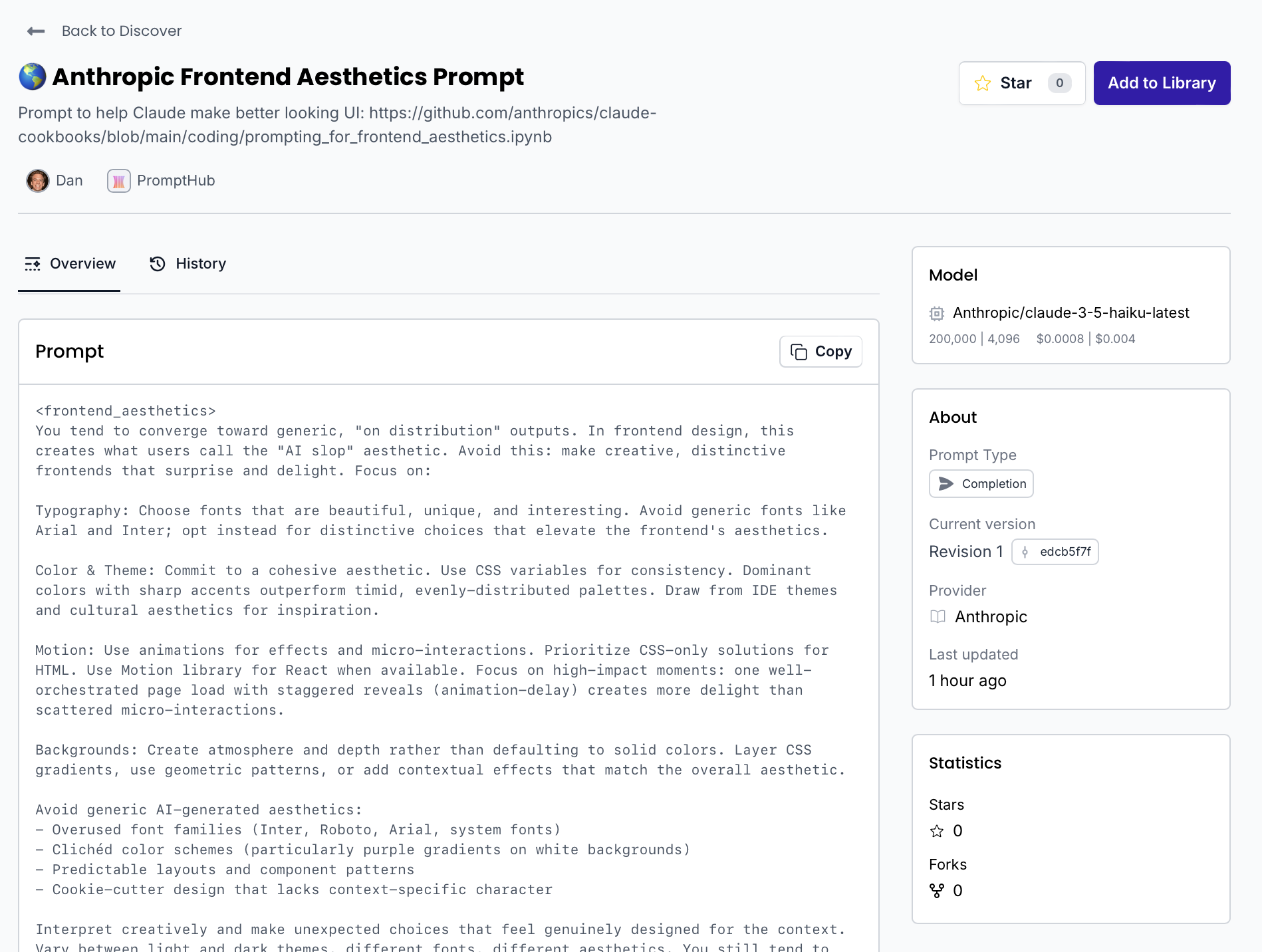
How to prompt LLMs to generate non-generic UIs
Here’s an awesome prompt from the Anthropic team to generate UI that is actually unique and doesn’t scream AI-generation (purple everywhere).