
Prompt engineering methods that reduce hallucinations
Easier to implement than RAG, faster than fine-tuning a model, three templates to get you going

Quick announcement. We just set up rewards for referrals🎉. Free stuff from us for helping to expand our community and the field of prompt engineering. More info here. I'd love to hear your thoughts on which rewards you'd find most beneficial. Let me know!
Alright, now on to the good stuff.
Speed, cost, and accuracy. Those are generally the three top concerns companies have when thinking about implementing AI/LLMs into their internal workflows or products. Let’s focus on that last one.
Models are getting better, but hallucinations are still a major problem. Regardless of what model you’re using, you’ll run into outputs that are hallucinations.
There are many ways to mitigate hallucinations: at the model level via fine-tuning, at the orchestration level via Retrieval-Augmented Generation (RAG), and at the prompt level via prompt engineering. While using multiple methods in conjunction can have compounding effects, RAG and fine-tuning can take some time to set up, so we’ll focus on the prompt engineering solutions.
3 methods, 3 templates, plenty of examples, takes less than 2 minutes to test.
Prompt Engineering Method #1: Step-Back Prompting
Arguably, the most important rule in prompt engineering is giving the model room to think, also known as Chain-of-Thought (CoT) reasoning. You don’t want to overly constrain the model. For example:

It is almost impossible to answer the first prompt without context about what you are developing on the web. Pushing the model to give a single answer doesn’t give it the opportunity to leverage its vast knowledge base.
The second prompt gives the model room to explore the pros and cons of various methods, and then come to a final conclusion. This leads to more thoughtful and accurate outputs.
CoT reasoning is great and takes on many forms when it comes to implementation. The simplest method is to add a statement like 'Take your time and think through the problem step-by-step.
Here are a few more examples from a paper we covered back in September: Large Language Models as Optimizers. You can check out our overview here.

Step-Back prompting outperforms typical CoT methods and is very simple to implement.
Step-Back prompting instructs the model to first think abstractly about concepts and principles related to the question, before diving into solving the question itself.

For example, let’s say the main question/problem we want the LLM to handle is “What strategies can improve my email campaign's open rates?” A step-back question could be, “How do email recipients decide which emails to open?” Thinking more broadly about the factors influencing users to open emails will help guide the model toward a comprehensive solution.
Step-Back prompting has been shown to outperform Chain-of-Thought (CoT) methods across various datasets, achieving up to 36% better results in some cases.
If you want to dive deeper, here is the full research paper, as well as our detailed rundown.
Additionally, you can experiment with Step-Back prompting yourself using our free template in PromptHub.

Prompt Engineering Method #2: Chain of Verification
Breaking down a question into subquestions is a great way to help guide the model along to a final answer, especially when the initial question was vague.
Chain-of-Verification (CoVe) prompting builds on this method by incorporating a verification loop to help reduce hallucinations and increase output accuracy. There are four steps:
The model generates an output to the original prompt
Based on the initial output, the model is prompted to generate multiple questions that verify and analyze the output from the original prompt
The set of verification questions are put through an LLM. The outputs are matched against the initial output.
A prompt is constructed with the original query and the verification question/answer pairs. The output from that prompt is the final prompt!

This method usually has a few prompts:
One for the original query
Another for the verification questions
A final prompt that brings various components together
We put together a single-shot prompt that performs on a similar level to the multi-prompt set up, and is much easier to use. You can access it in PromptHub here.

CoVe prompt template:
Here is the question: {{Question}}.
First, generate a response.
Then, create and answer verification questions based on this response to check for accuracy.
Think it through and make sure you are extremely accurate based on the question asked.
After answering each verification question, consider these answers and revise the initial response to formulate a final, verified answer. Ensure the final response reflects the accuracy and findings from the verification process.
For more info, feel free to check out the full paper here, or our detailed rundown here.
Prompt Engineering Method #3: According to…
I saved my favorite method for last. “According to...” prompting is extremely easy to implement and does a great job at reducing hallucinations.
It is based on the concept of directing the model to retrieve information from a particular source when generating an output.
By doing this, you increase the probability that the model will pull from that trusted source, leading to more accurate answers and less hallucinations.

Here are a few more examples:
Legal: "Drawing insights from the commentary in the Legal Affairs Digest..."
Healthcare: "Based on discoveries reported in the Global Medical Review..."
Entertainment: "Taking cues from the recent critiques in Entertainment Pulse..."
Finance: "Referencing the latest economic insights from Financial World Review..."
Tech: "Gleaning knowledge from the updates in Tech Innovations Magazine..."
Educational: "Following the frameworks discussed by the Global Education Forum..."
Environmental: "Incorporating findings from the Environmental Conservation Chronicles..."
You can try out the template in PromptHub here.
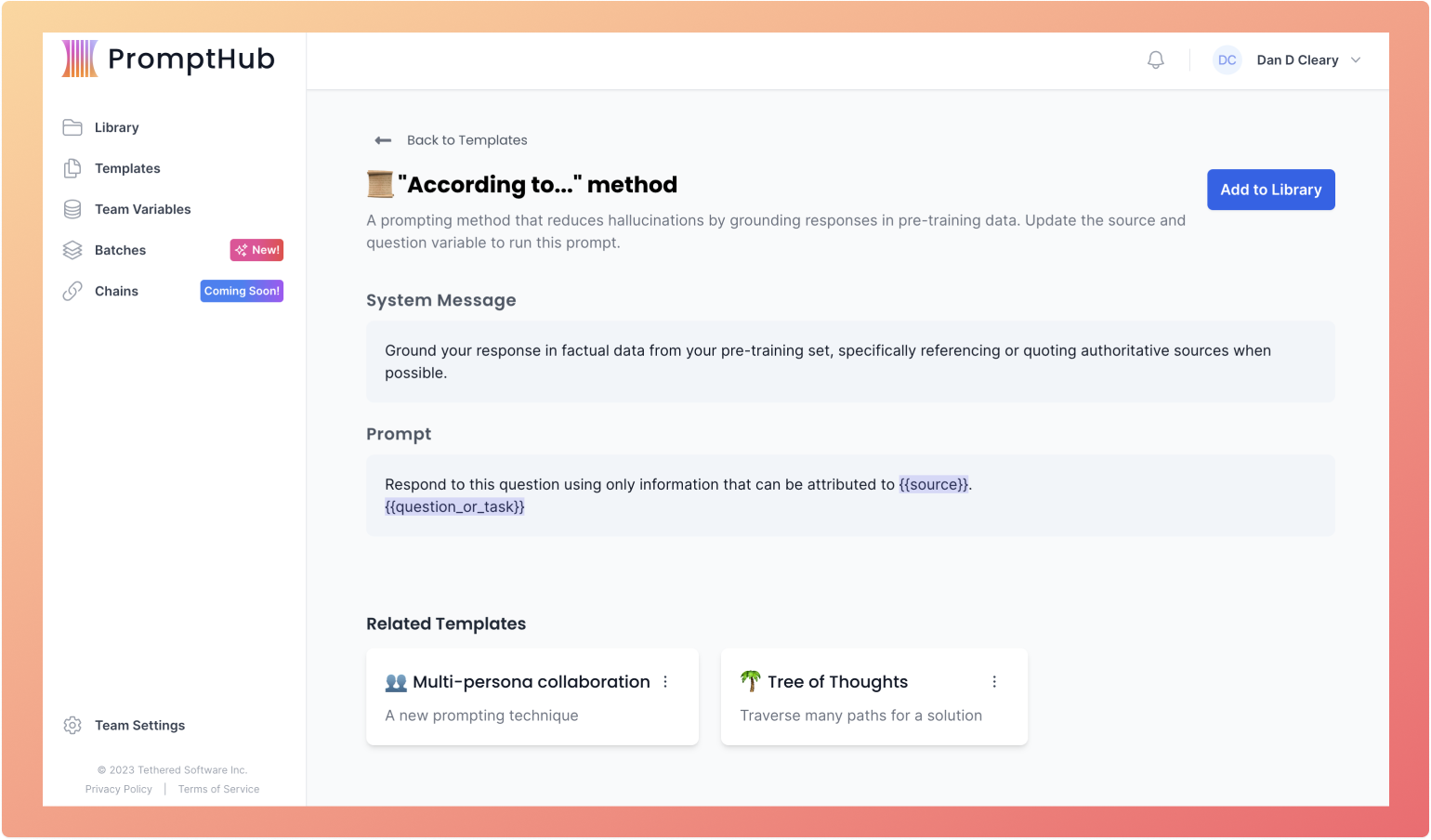
The research team that ran experiments with According to prompting found they were able to improve accuracy by up to 20% in some cases. If you want to check the full paper, click here. We also put together a in-depth analysis of this method and its experimental results here.
That’s it for this week! Feel free to follow me on LinkedIn here for more posts this week about how to reduce hallucinations when generating outputs from LLMs.