
Picking the right model for the right task
Plus some quick thoughts on Grok 4

It seems like every week a new LLM launches (more on Grok 4 later). With more and more models, the question of which model to use and when becomes more challenging. Every model claims to be the best in some narrow set of benchmarks, but you also probably don’t need the smartest reasoning model just to tell you simple information.
On top of that, the model descriptions from the LLM companies are…lacking.
For example:
GPT-4o: Fast, intelligent, flexible GPT model
GPT-4.1 mini: Balanced for intelligence, speed, and cost
Picking the best model for each task is easier said than done, but there are a few options, which we’ll dive into, including a super cool new method that uses a 1.5B model (Arch-Router) to route queries based on user preferences!
Different types of LLM routers
Intent/Embedding-Based: Embed each user query and run a semantic similarity vector search to see which topic it relates to.
Cost/Performance-Based: Use past benchmarks or cost–accuracy curves to decide if a cheap model can get the job done, or if you should escalate to a larger one. Saves budget but loses out on subjective preferences.
Rule-Driven: Hand-coded if/else or YAML/JSON configs map patterns (endpoints, keywords) directly to models. Ultra-fast and transparent, but a maintenance nightmare as use cases grow.
Preference-Aligned: Write plain-English policies (e.g., “legal_review → GPT-4o-mini”) and use a routing model that ingests those rules plus the user query and picks the best match. Flexible, human-interpretable, and no retraining needed. This is the approach behind Arch-Router.
Arch-Router
Arch-Router flips routing on its head by using plain-English policies instead of benchmarks or hard-coded rules. You define a small set of (identifier, description) pairs, plus a model map:
C = {
(“code_gen”,“Generate code snippets or boilerplate.”),
(“summarize”,“Produce a concise summary of this text.”),
(“default”,“Fallback for any other queries.”)
}
T(code_gen) = Claude-sonnet-3.7
T(summarize) = GPT-4o
T(hotel_search) = Gemma-3
T(default) = Qwen2.5-4B
Under the hood, Arch-Router is a fine-tuned Qwen 2.5 (1.5B) model. At runtime, it ingests:
Your list of policies
A rolling window of recent conversation turns
The user’s most current query
…all in one prompt (below).
It then outputs the best policy identifier (e.g. legal_review), which your system maps to the target LLM (like GPT-4o-mini) for the final response.
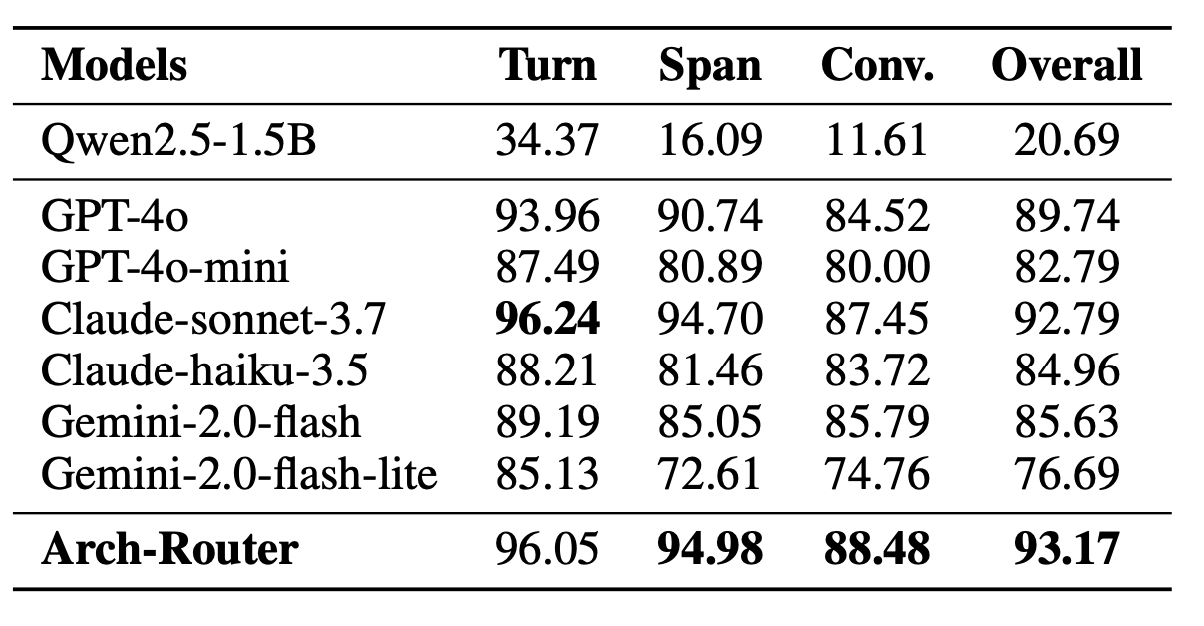
This design makes it easy to add, remove, or tweak policies on the fly. Impressively, Arch-Router, even though it is a much smaller, fine-tuned model, is basically able to achieve the same level of performance as Claude 3.7 Sonnet. All while only adding ~50ms of latency.
Example Arch-Router prompt
You are a helpful assistant designed to find the best suited
route.
You are provided with route description within
<routes></routes> XML tags:
<routes>
\n{routes}\n
</routes>
<conversation>
\n{conversation}\n
</conversation>Your task is to decide which route is
best suit with user intent on the conversation in
<conversation></conversation> XML tags.
Follow the instruction:
1. If the latest intent from user is irrelevant or user
intent is full filled, respond with other route {"route":
"other"}.
2. Analyze the route descriptions and find the best match
route for user latest intent.
3. Respond only with the route name that best matches the
user’s request, using the exact name in the <routes> block.
Based on your analysis, provide your response in the
following JSON format if you decide to match any route:
{"route": "route_name"}
Wrapping up with a few thoughts on Grok 4
So Grok 4 just dropped, two quick thoughts:
XAI has entered the game in a meaningful way
Currently, it holds state of the art performance on ARC-AGI.
It has no extra pre-train compute, but RL increased by 10x
The fact that Grok 4 is the same base model as Grok 3 is really interesting for the industry. You can see in the graph below that the training compute was split 50/50 between pre-training and RL.
