


o3-mini overview
How it compares to R1 and o1. Plus a free webinar next week

DeepSeek’s R1 time on top of the benchmarks was short-lived. Just a few days after DeepSeek made global news with its highly performant reasoning model, OpenAI released o3-mini. o3-mini is now at the center of attention, not just because it may be the best reasoning model out there, but also because it’s incredibly cost-efficient.
In this post, we’ll cover some high-level information about o3-mini, compare its performance side by side with R1, and walk through some personal tests that highlight how much progress has been made since OpenAI’s o1,
Before we get into that, if you’re not sick of hearing about DeepSeek, OpenAI, and reasoning models, I’m hosting a free webinar next week with Mucker Capital. Totally free, grab a ticket here.

o3-mini at a Glance
Alright, let’s take a look here.
Specs
Provider: OpenAI
Release Date: January 31, 2025
Knowledge Cut-off: October 2023
Context Window: 200,000 tokens
Max Output: 100,000 tokens (highest in the industry)
Function (Tool) Calling: Yes, so it can leverage external APIs or code snippets
Vision Support: No
Multilingual: Yes, though primarily optimized for English
Fine-Tuning: No
New reasoning effort parameter: Choose between low, medium, and high reasoning
Developer messages: Developer messages appear to be a simple rebranding of the old ‘system’ role. As of a few days ago, sending messages with the role set to ‘system’ still worked seamlessly with o3-mini.”
Cost Structure
Input Tokens: $1.10 per 1M tokens (that’s $0.0011 per 1k)
Output Tokens: $4.40 per 1M tokens (or $0.0044 per 1k)
Note: “Reasoning” tokens count as output tokens, so you pay the same rate for them.
o3-mini is ~93% cheaper than o1
For more model-related info, or for information about other models, feel free to check out our LLM model directory.
How does o3-mini Stack Up Against R1?
OpenAI’s official launch post for o3-mini showcased how o3-mini, at varying reasoning effort levels compared to its other reasoning models, like o1, and o1-mini.
I pulled data from the R1 paper and made some graphs of my own.
Usual disclaimers that benchmarks aren’t perfect, etc. You can and should run your own tests across these models, which we support in PromptHub as of this week.
Head-to-Head Benchmarks
AIME (Math Competition Problems)

o3-mini-high: 87.3%
DeepSeek R1: 79.8%
o3-mini’s math chops shine here.
GPQA Diamond (PhD-Level Science Q&A)

o3-mini-high: 79.7%
DeepSeek R1: 71.5%
R1 can’t quite match o3-mini’s specialized reasoning.
Codeforces ELO (Programming Contests)

o3-mini-high: 2130
DeepSeek R1: 2029
Small but meaningful edge for o3-mini in coding challenges.
SWE Verified (Software Engineering Tasks)

o3-mini-high: 49.3%
DeepSeek R1: 49.2%
Basically a tie—just a 0.1% gap.
MMLU (General Knowledge, Pass@1)

o3-mini-high: 86.9%
DeepSeek R1: 90.8%
R1 holds the advantage for broad domain coverage.
Math (Pass@1)
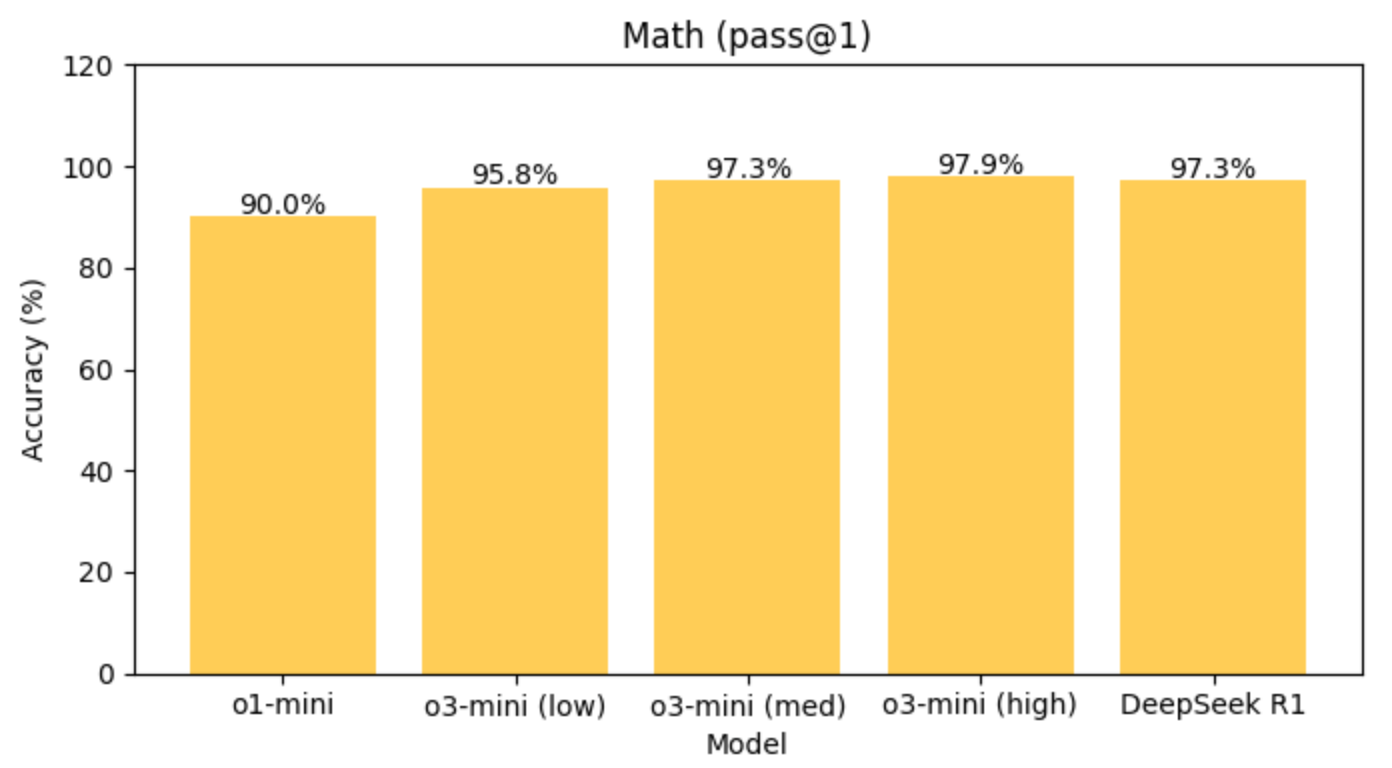
o3-mini-high: 97.9%
DeepSeek R1: 97.3%
Razor-thin win for o3-mini on raw math accuracy.
SimpleQA

o3-mini-high: 13.8%
DeepSeek R1: 30.1%
R1 dominates in straightforward, fact-based Q&A.







When you lay out these seven benchmarks, o3-mini-high takes five while R1 wins two.
My personal tests
A pelican riding a bicycle
A test that I’ve stolen from Simon Willison is sending the following prompt to a model:
Generate an SVG of a pelican riding a bicycle
o3-mini

o1

R1

I think R1 takes the win here for me. It did the best job of individually creating the bike and pelican, and also placing them together. Take that benchmarks!
Hard math problem
Another prompt I like to use to test these models is:
If a > 1, then the sum of the real solutions of √(a - √(a + x)) = x is equal to.
Here’s how long each model took to complete it (they all got it right)
o1: 7 minutes
R1: 4 minutes
o3-mini-medium: 1m 27s
o3-mini-high: 1m 25s
Wrapping up
o3-mini proves that bigger isn’t always better. By combining a massive context window, flexible “reasoning effort” settings, and much lower costs than previous OpenAI models, it delivers top-notch performance in math, coding, and advanced logic tasks. Now get out there and run some tests of your own!