
Increase performance by repeating LLM calls
Sometimes throwing more API calls at a problem is the easiest way to increase accuracy

There are a lot of ways to increase performance when working with Large Language Models. Prompt engineering methods, like Chain of Density can increase the quality of summaries. EmotionPrompt can increase accuracy by tapping into what appears to be human behavior reflected in LLMs.
Another way to increase performance (and confidence) is by increasing the number of calls made to an LLM for a single task, and sampling the various responses.
This helps decrease the chances of getting one “rogue” or wrong output.
This method of generating multiple outputs and selecting the most consistent answer is called Self-Consistency Prompting. First written about in March 2023 by a team of researchers from Google, this method can increase accuracy through brute force.
How Self-Consistency Prompting works
Self-Consistency prompting is a three step process.
Create the initial prompt (can use Chain-of-Thought/Few Shot prompting for optimal performance)
Run the prompt many times to generate multiple outputs
Choose the most consistent answer via some defined set of rules

As you now know, Self-Consistency Prompting is typically done via multiple LLM calls. We put together a single-shot prompt template that can be used as a starting point. Here’s a link to the free template.

Using consistency as a proxy for confidence
An additional benefit for self-consistency prompting is that it can be used as a proxy for confidence.

In this case consistency means the percentage of outputs that are the same as the final answer. There is a high correlation with consistency and accuracy which can help developers. The higher the consistency the more confident you can be in the output accuracy.
When to use Self-Consistency Prompting
Self-Consistency prompting is particularly helpful when you know what the ground truth answer should be, such as math equations or classification problems. It falls short on tasks where the outputs are not uniform, such as summarization tasks.
The researchers at Google noticed this and followed up with a paper to address these problems, titled Universal Self-Consistency.
Universal Self-Consistency (USC)
USC is very similar to self-consistency prompting aside from the final evaluation step. Rather than using a rules-based approach to judge the outputs, USC uses an LLM to make the final assessment.
USC Steps
Similarly, Universal Self-Consistency prompting is a three step process. The key difference is in the third step.
Create the initial prompt (can use CoT/few shot prompting for optimal performance)
Run the prompt many times and concatenate all the outputs
Use an LLM to select the most consistent response
In this way, USC eliminates the need to count exact answer frequencies like standard self-consistency does, instead relying on the LLM's ability to assess consistency among different responses.

Another benefit of USC is the flexibility it provides by using a prompt for the evaluation. You could replace “consistent” in the prompt above with whatever adjective you want to optimize for.
For example, in the original study, they changed “consistent” to “most detailed” and were able to increase performance.

Implementing USC with no-code
Let’s create a prompt chain in PromptHub to use USC from end-to-end
We’ll use USC to select the best option amongst multiple social media post generations (LinkedIn specifically).
Step 1- Create prompt to generate LinkedIn posts.
We’ll use this template in PromptHub.
Step 2 - Generate multiple outputs
Next, we’ll build a prompt chain that will create a number of options of posts.
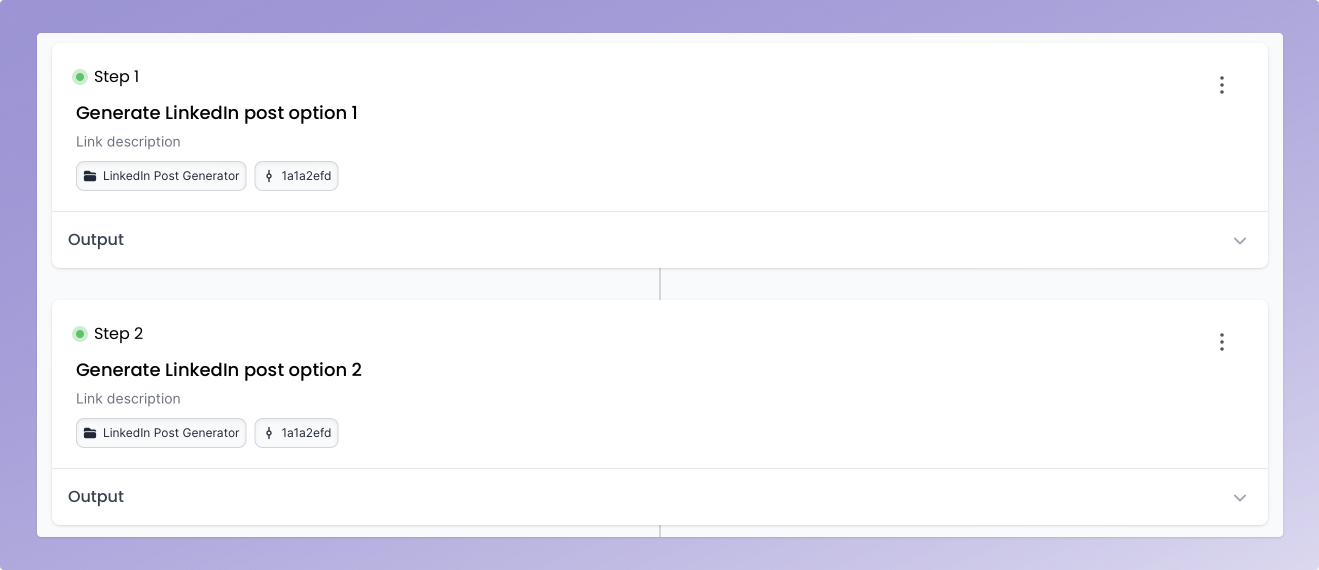
Step 3 - Use the USC prompt to select the most consistent
We’ll use the USC template (access it here.) as the last step in our chain.

We’ll map the three outputs from the previous steps into the USC prompt to judge which post is the most consistent.

And we’re done! A full implementation of USC without writing a single line of code.
Conclusion
Sometimes throwing more money at a problem can help. This often takes the shape of using a more expensive model to increase performance, but it can also involve generating multiple outputs to enhance confidence in the results. Implementing USC can help you get higher accuracy across a wide array of tasks.
Hope this helps you get better outputs!
Wouldn't this increase the latency?