
How to actually use GPT-5
A few easy tips to get better outputs when using GPT-5

The response to GPT-5 has been mixed, to say the least. Some of this comes down to non-model performance reasons, like a few missteps in how OpenAI launched the models, but part of the backlash is tied directly to the model itself.
GPT-5 is different in many ways compared to previous OpenAI models like GPT-4o and the o-series. It shares more similarities with GPT-4.1 when it comes to how you prompt and interact with it. GPT-5 is extremely steerable through the prompt, for better and for worse.
The Complete Guide to GPT-4.1: Models, Performance, Pricing, and Prompting Tips
When using GPT-5 via the API, aside from the wording of the prompt itself, there are three levers that matter most:
reasoning_effort — how hard the model thinks
verbosity — how long the final answer is
tool preambles — how transparently it plans and reports progress
We’ll dive into each, including how to tune older prompts to work better with GPT-5.
1. Controlling Eagerness with reasoning_effort
The reasoning_effort parameter isn’t new, but GPT-5 introduces a fourth value: minimal. You can now set it to:
minimal
low
medium
high
For faster answers, use minimal or low. On top of that you can reinforce (or even override) the API setting directly in your prompt instructions. This is a recurring theme with GPT-5: because the model is so steerable, the prompt often matters just as much as the parameter.
Here’s an example of adding reasoning constraints directly into the prompt:
<context_gathering>
Goal: Collect just enough context to act quickly.
Method:
- Begin broad, then branch into narrower sub-queries.
- Run varied queries in parallel; read only the top hits. Deduplicate results to avoid repeats.
- Don’t overspend on context—limit to one focused batch if more depth is needed.
Stop early when:
- You can point to the exact content to edit/change.
- Top hits converge (~70%) on the same area or answer.
Escalate once:
- If results conflict or scope is unclear, run one more refined batch, then move on.
Depth:
- Trace only the symbols you will modify or directly depend on. Skip unnecessary transitive exploration.
Loop:
- Batch search → sketch minimal plan → execute.
- Only re-search if validation fails or new gaps appear. Favor action over more searching.
</context_gathering>
IMPORTANT:
reasoning_effortaffects not just how much reasoning text the model produces, but also how readily it decides to call tools.
On the other hand, for complex, multi-step tasks, you’ll want to set reasoning_effort to high and give persistence reminders in your prompt:
<persistence>
- Keep going until the task is fully resolved.
- Don’t hand back on uncertainty; assume, note it, continue.
- Only stop when all sub-requests are done.
</persistence>
You’ll need to be careful when asking GPT-5 to sustain reasoning for long periods. Without boundaries, it can drift into rabbit holes. That’s why it’s important to always include an escape hatch, a clear condition that tells the model when to stop.
Here’s an example you can drop into a prompt to cap reasoning loops:
<uncertainty_policy>
If unresolved after X context-gathering rounds, produce a Provisional recommendation.
List assumptions + unknowns. Label clearly as "Provisional".
</uncertainty_policy>2. Making Work Visible with tool preambles
Tool preambles are a new API feature introduced with GPT-5. They let the model send intermittent updates while it’s reasoning and calling tools. This helps keep the user in the loop of what the model is doing, especially when it’s working on longer tasks.
All you need to do is add the following to your request:
"reasoning": { "summary": "concise" } //other options are "auto" and "detailed"
As we saw before, you can reinforce the tool preambles in your prompt as well.
<tool_preambles>
- Restate the user’s goal before tool use.
- Outline a short step-by-step plan.
- Narrate steps briefly as you execute.
- End with a crisp “What we did” summary.
</tool_preambles>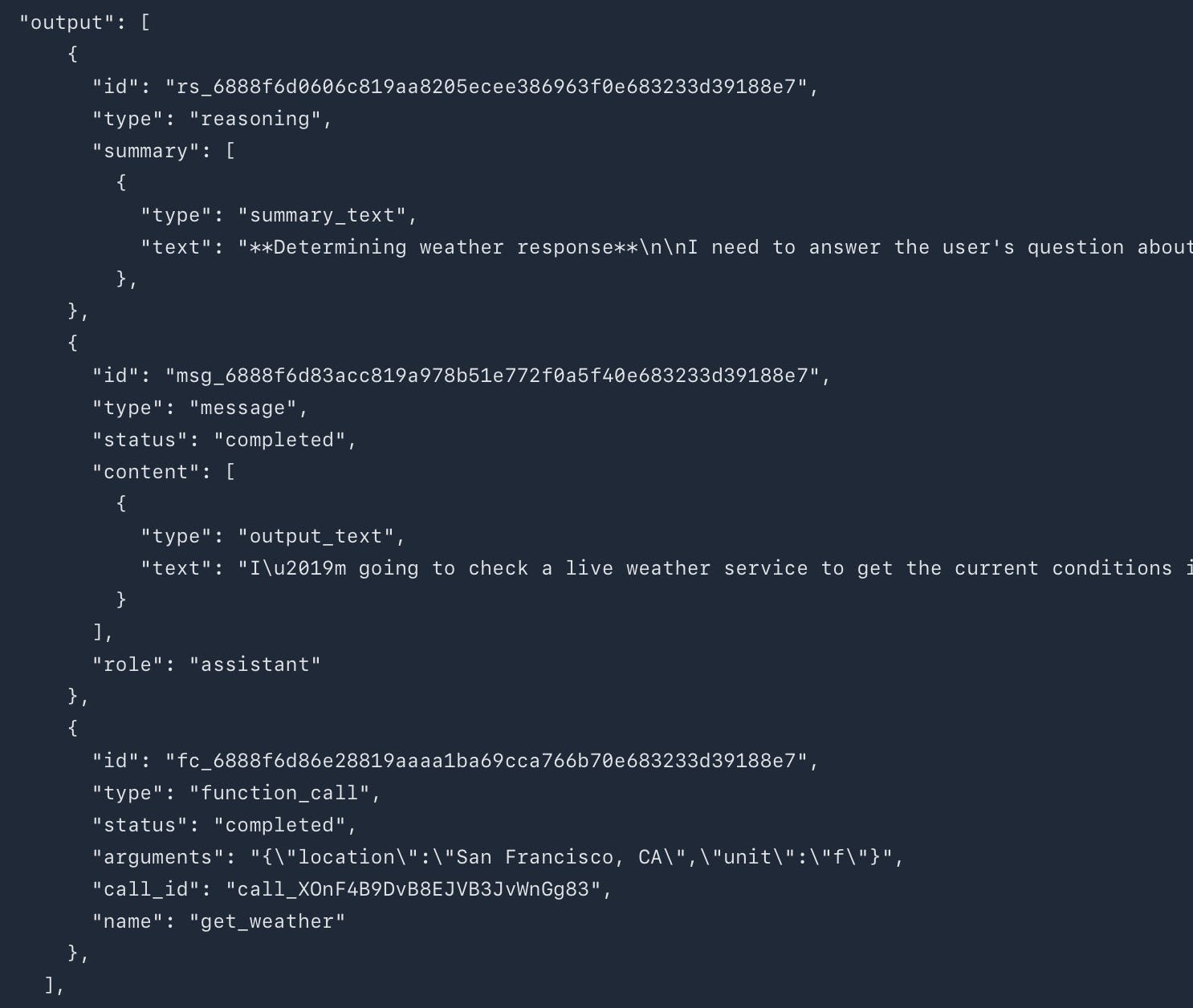
3. Shaping Answers with verbosity
verbosity is the other new API parameter introduced with GPT-5. It controls the length of the final output (but not tool calls or internal reasoning).
low → crisp, snappy (default for chat)
medium → balanced
high → long-form, teaching mode
Like reasoning_effort, verbosity can also be reinforced or overridden in your prompt instructions.
A good real-world example comes from Cursor. When they first rolled out GPT-5 internally, they ran into two opposite issues:
Chat responses were too long and slowed down UX.
Code outputs inside tools were too short to be useful.
Their fix:
Set global verbosity to low so everyday chat responses stayed concise.
Add explicit prompt instructions for high verbosity when generating code, ensuring outputs were clear and well-structured.
This combination gave them the best of both worlds: snappier interactions in chat, and more complete, readable code in tools.
- Write code for clarity first.
- Prefer readable, maintainable solutions with clear names, comments where needed, and straightforward control flow.
- Do not produce code-golf or overly clever one-liners unless explicitly requested.
- Use high verbosity for writing code and code tools.Tuning Old Prompts for GPT-5
One of the biggest reasons GPT-5 can feel “slower” is that it’s naturally more introspective and proactive when gathering context.
Why Old Prompts Break
Over-instructing on reasoning: A lot of GPT-4o prompts included reasoning instructions like “Be THOROUGH” or “think step-by-step”. With GPT-5, that language encourages over-searching, repetitive tool calls, and wasted reasoning tokens (see our guide on prompt engineering with reasoning models).
No stop conditions. Older prompts often lacked explicit boundaries for when to stop reasoning or searching. GPT-5, left unchecked, keeps digging.
Contradictions pile up. Because GPT-5 follows instructions so precisely, even small contradictions or redundancies can degrade output quality.
Fixes That Work
Soften or remove reasoning language → Replace “be thorough” with lighter phrasing like:
<uncertainty_policy>
Gather context until you can take first action.
If unclear after X attempts, produce a Provisional recommendation with assumptions.
</uncertainty_policy>
Add explicit stop rules → GPT-5 benefits from a clear escape hatch. This prevents endless searching loops.
Lean on persistence reminders → Instead of telling it to “be exhaustive,” tell it to keep going until the task is resolved, then stop.
Real-World Example: Cursor
Cursor had a snippet in one of their main prompts:
<maximize_context_understanding>
Be THOROUGH when gathering information. Make sure you have the FULL picture before replying. Use additional tool calls or clarifying questions as needed.
</maximize_context_understanding>
This worked on older models, but with GPT-5 it caused the model to do way too many searches and spiral out of control.
The fix: they removed the maximize prefix and replaced it with a gentler directive:
<context_gathering>
Gather only the context required to act.
Avoid repeating searches.
If unsure, return a Provisional answer with assumptions noted.
</context_gathering>
Result: GPT-5 stopped wasting tool calls, made smarter decisions about when to rely on internal knowledge, and delivered faster, higher-quality responses.
Putting it all together
Your GPT-5 cheat sheet:
Be specific. Avoid ambiguity.
Tune effort. Minimal/low = speed; high = depth. (this requires iteration)
Add preambles. Plan → progress → summary.
Set stop conditions. Prevent runaways.
Iterate small. Change one lever at a time.
P.S. We’re hosting the prompt engineering conference in London this year, tickets still available here.