
GPT-5 and OpenAI's Open Source Models
GPT-5 is a game changer

TL;DR
GPT‑OSS gives us Apache‑2 licensed, open‑weight models (120 B & 20 B) that punch at GPT‑o4‑mini levels while running on a single H100. Aka, you can run the large model on your laptop and the small one on your smart phone.
GPT‑5 lands in the API and ChatGPT with a 400,000 token window, full multimodality, and the best structured‑reasoning and tool calling we’ve seen. Three versions: GPT-5, GPT-5-mini, and GPT-5-Nano. Cheaper than 4o!
API updates: A few new parameters to discuss.
Why the open-source models matter
OpenAI has always kept its crown jewels behind an API gateway. August 2025 breaks that pattern and gives us the best open-source model in the world. The OSS drop alongside GPT-5 feels like a scorched earth approach. OpenAI is releasing, for free, a model that is extremely performant, while also releasing the best model on the planet in GPT-5. This means that for any premium use case, you would reach for GPT-5, while for less important use cases you could, in theory use one of their OSS models for free.
In practice, even open-source models that are performant aren’t used very often. Companies would rather just pay the API costs for a cheaper proprietary model.
Inside GPT‑OSS (120 B & 20 B)
Key specs
120 B (Mixture‑of‑Experts) — 120 B total parameters, only 5 B active per token; 128 K context; runs on a single 80 GB H100 or a Mac with 96 GB unified memory.
20 B — 20 B total parameters, 3.6 B active per token; same 128 K context; works on a 16 GB consumer GPU or even a high‑end phone.
Benchmarks & early impressions
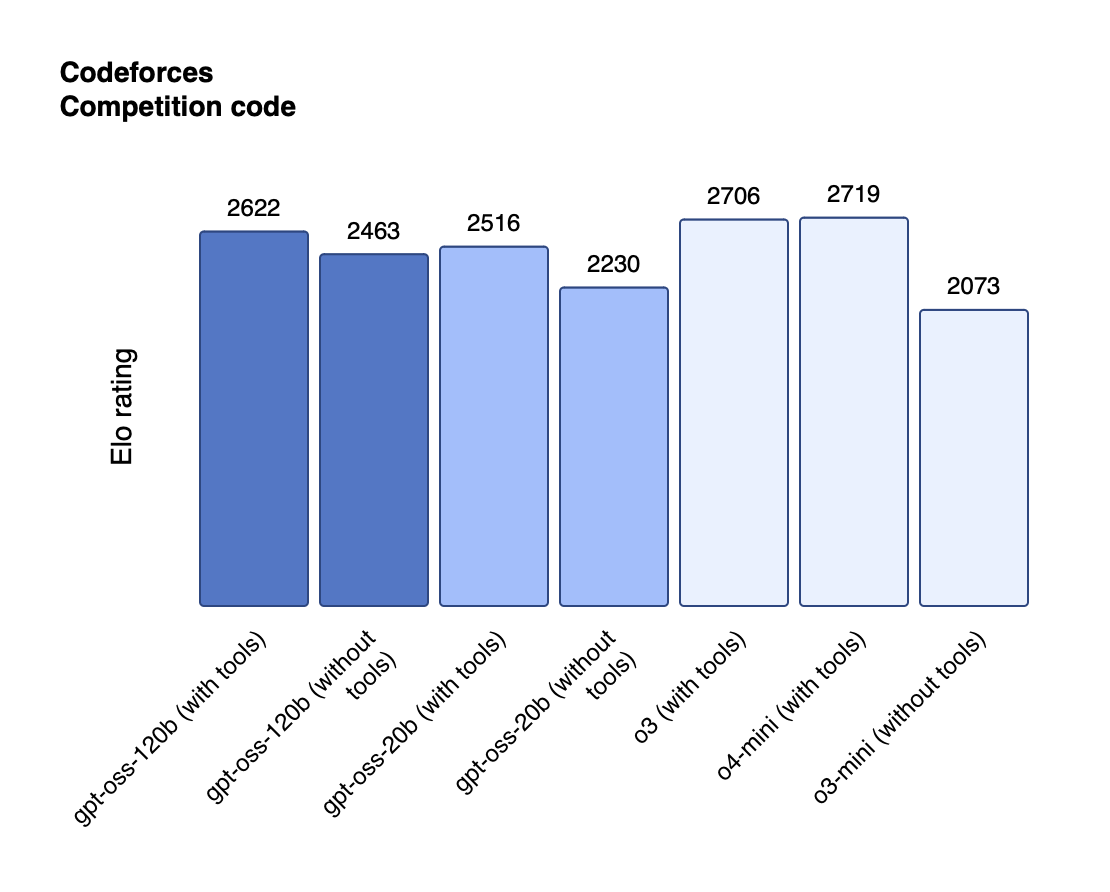
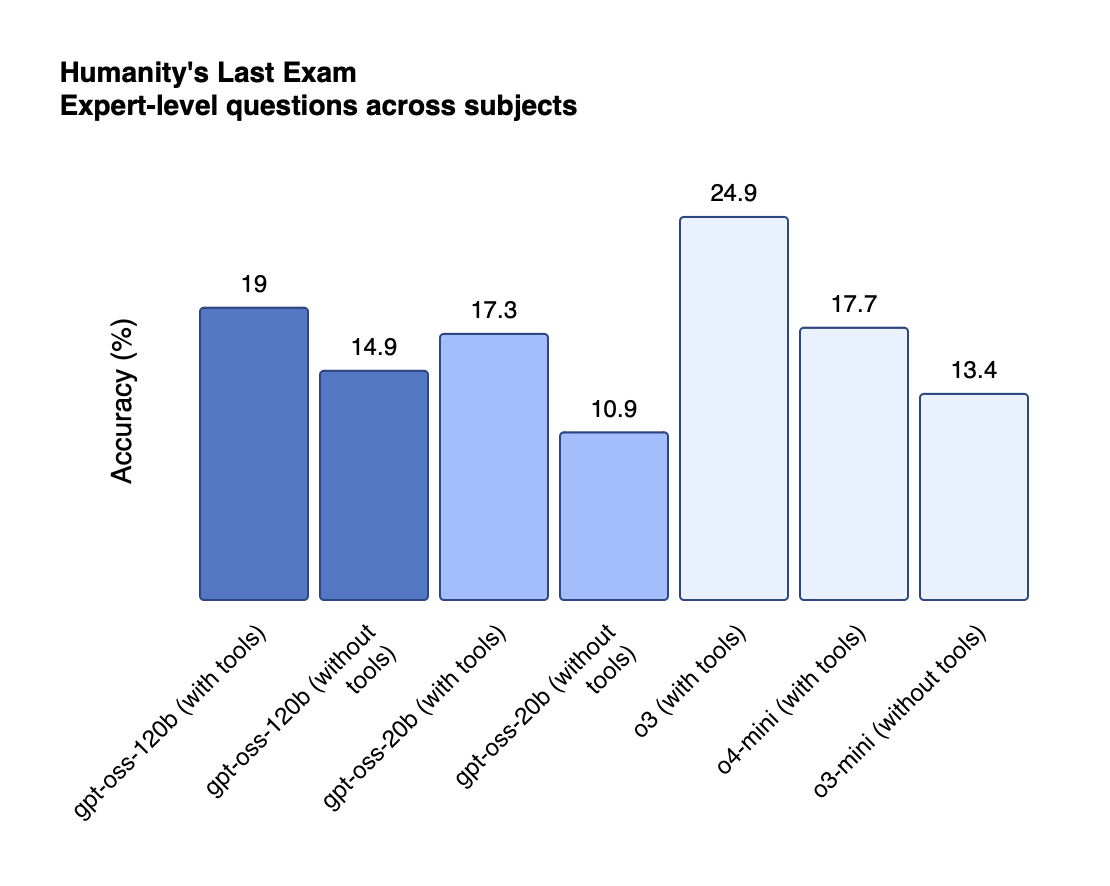
Reasoning: Near‑parity with o4‑mini (120 B) and o3‑mini (20 B) on MMLU, GPQA, Codeforces, graphs below!
Released Harmony – an open-source formatting layer that auto-translates “vanilla” JSON function calls into the bracket-bar syntax GPT-OSS (and other new models) expect, so your existing tools keep working without manual prompt surgery.
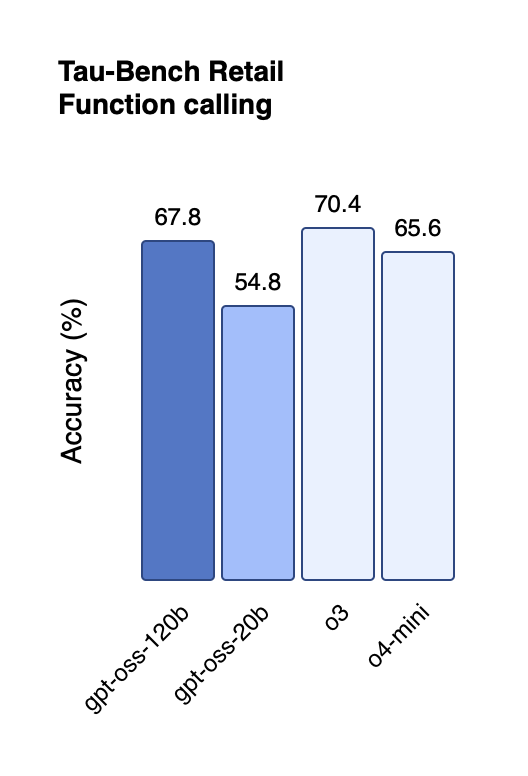
Tool use: Passes TA‑Bench at ~ 68 F1 when calls are pre‑formatted with Harmony.
Safety: No supervised CoT; chain‑of‑thought is raw and visible. OpenAI recommends summarizing before display.
GPT‑5: the new frontier model
Three flavors (pricing & focus)
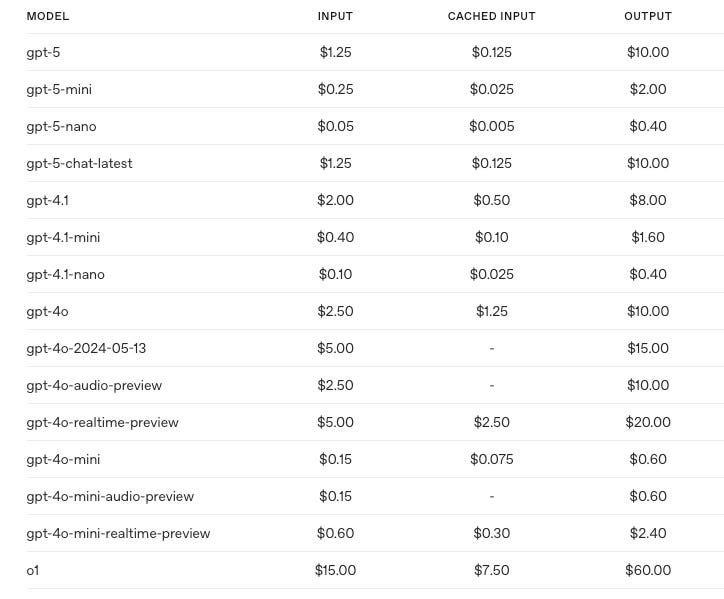
GPT‑5 — flagship. Pricing: $1.50 in / $5.00 out per million tokens.
GPT‑5‑mini — optimized for chat UIs and product UX. $0.80 in / $2.50 out.
GPT‑5‑nano — tuned for real‑time apps; lowest latency. $0.40 in / $1.25 out.
All three share a 400k token context window and max outputs of 128k tokens
Some fun stuff
reasoning_effort— now can be set to minimal to get faster answers. Previously the options were low, medium, and high. This seems like an additional option, not a replacement for any previous ones. If not specified, effort defaults to medium.Custom Tools (API): Let GPT-5 return plain-text (or any DSL) arguments instead of rigid JSON, with an optional regex/grammar guardrail.
Verbosity parameter: New top-level `verbosity=low | medium | high` that controls how succinct or expansive GPT-5’s response will be
Tool‑calling proficiency — 96.7 % success on τ²‑bench telecom; roughly ½ the error rate of prior frontier models. This is huge and the biggest thing I’ve noticed from playing around with the model.
Prompting cheat‑sheet key points
Calibrate agentic eagerness – adjust
reasoning_effortand spell out context-gathering rules or tool-call budgets to make GPT-5 either more conservative or more autonomous.Add “tool preambles” – have the model restate the goal, outline a plan, and narrate progress so long agentic roll-outs stay transparent.
Use structured XML-style blocks (e.g.,
<context_understanding_spec>) and softer wording; overly “be THOROUGH” instructions can cause wasteful tool use.Control answer length with the new
verbosityparameter or plain-language overrides; GPT-5 eagerly follows tone, verbosity and tool-calling directives.Remove conflicting or vague instructions – GPT-5 will burn tokens trying to reconcile them, so review prompts (or run the Prompt Optimizer) to catch contradictions.
Leverage minimal reasoning for latency-sensitive tasks, but add a brief thought summary, rich preambles and explicit planning to offset the reduced reasoning depth.
Stick to canonical tooling – use
apply_patchand related file tools for code edits to match GPT-5’s training distribution.Let GPT-5 meta-prompt itself – ask it to suggest precise additions or deletions that fix prompt shortcomings; many teams ship these edits directly.
Wrapping up
This was a quick dive into the models, but nothing can replace actually testing them out yourself! Personally, I was facing some weird type issue when building a Raycast extension for PromptHub that Claude 4 Opus just couldn’t figure out. GPT-5 fixed it in one shot…something is different about this model and it’s exciting.