


GPT-4 v. University Physics Students
A real world case study of a head-to-head, controlled, match up of humans versus AI

There’s no way around it, AI will be an extremely disruptive technology. It will change the way certain jobs are done. No one seems to debate that. Will it be 12 months? 5 years? or 10? That’s harder to know.
Seeing demos of certain products can feel magical, and big tech companies will launch new models that push the boundaries on benchmarks. But demos and benchmarks only get you so far. We need real-world, empirical data.
Thanks to a few researchers at Durham University we have a glimpse into a controlled battle of AI vs Human on a “knowledge work” type of task.
The paper is titled: “A Comparison of Human, GPT-3.5, and GPT-4 Performance in a University-Level Coding Course”. The researchers set up an experiment to evaluate the performance of GPT-3.5, GPT-4, and college-level students on a physics coding assignment (Python). They tested the models both with and without prompt engineering.
Additionally, after the teachers blindly graded the results, they were also asked to guess if the given submission was written by AI or a human.
Let’s see who won this battle, man or machine.
Experiment 1: Performance
Some quick background. The students in the study took part in a 10-week physics course that had a fair amount of programming throughout.
The researchers compared 50 student submissions to 50 submissions from AI. Each submission was graded blindly by three judges, to make a total of 300 data points.
Methods
There were a total of 6 methods used to create the homework submissions. Ten submissions from each of 5 AI methods, and 50 submissions from the students. Here were the 6 total methods:
GPT-3.5 raw:
GPT-3.5 with prompt engineering: The submitted text was modified to follow certain prompt engineering guidelines (see details in table below)
GPT-4 raw: Used the gpt-4-1106-preview model (aka, GPT-4-Turbo)
GPT-4 with prompt engineering: The submitted text was modified to follow certain prompt engineering guidelines (see details in table below)
Mixed: Randomly mixes contributions from students and GPT-4 with prompt engineering.
Student: 50 student submissions, randomly selected

Limitations
No way to rule out completely that the students didn’t use AI to help them
The researchers had to preprocess some data to make the prompts work for the LLMs. For example, converting tables to Python dictionaries. This highlights certain limitations of the models and skew this head to head match up slightly.
Results

Humans stay on top for now, with an average score of ~92% compared to the best performing AI method (GPT-4 + prompt engineering) at ~82%
Prompt engineering significantly enhanced performance: it raised GPT-4's performance by approximately 13% and GPT-3.5's by approximately 58%.
GPT-4, 71.9%, blows GPT-3.5, 30.9%, out of the water
In addition to the limitation mentioned above regarding data preprocessing for the LLMs, the researchers provided additional assistance to the models. In instances where the outputs either contained broken code or no Python code at all, the researchers reran the prompts until they obtained 10 functional submissions.
Experiment 2: AI or human?
After scoring the homework submissions, the graders were asked to record whether they thought the submission was AI or human. They used a Likert scale with 4 options:
Definitely AI (score:0)
Probably AI (score:1)
Probably Human (score:2)
Definitely Human (score:3)

Average scores:
GPT-3.5: .033
GPT-3.5 with prompt engineering: .2
GPT-4: .467
GPT-4 with prompt engineering: 1.167
Student: 2.367
Converting the Likert scale to a binary “AI” or “Human” ranking system, the graders had an average accuracy rate of 85%
As expected, submissions with prompt engineering applied tended to sound more “human-like”.
The graders were able to pick up on a pattern amongst the AI-generated submissions. The submissions tended to have some slight misalignments in format and unusual font sizes. Comparatively, the student submissions tended to use more bold and unconventional design choices.
For example, AI outputs used very standard colors for the tables generated while the students tended to use varying color palettes.
These minor creative considerations highlight an important point about creativity. LLMs are trained on massive amounts of data, generate tokens based on probabilities and therefore converge to the general mean. While for a single human submission, there is much more room of subjectivity and individual creative decisions.
Moving on, last graph.
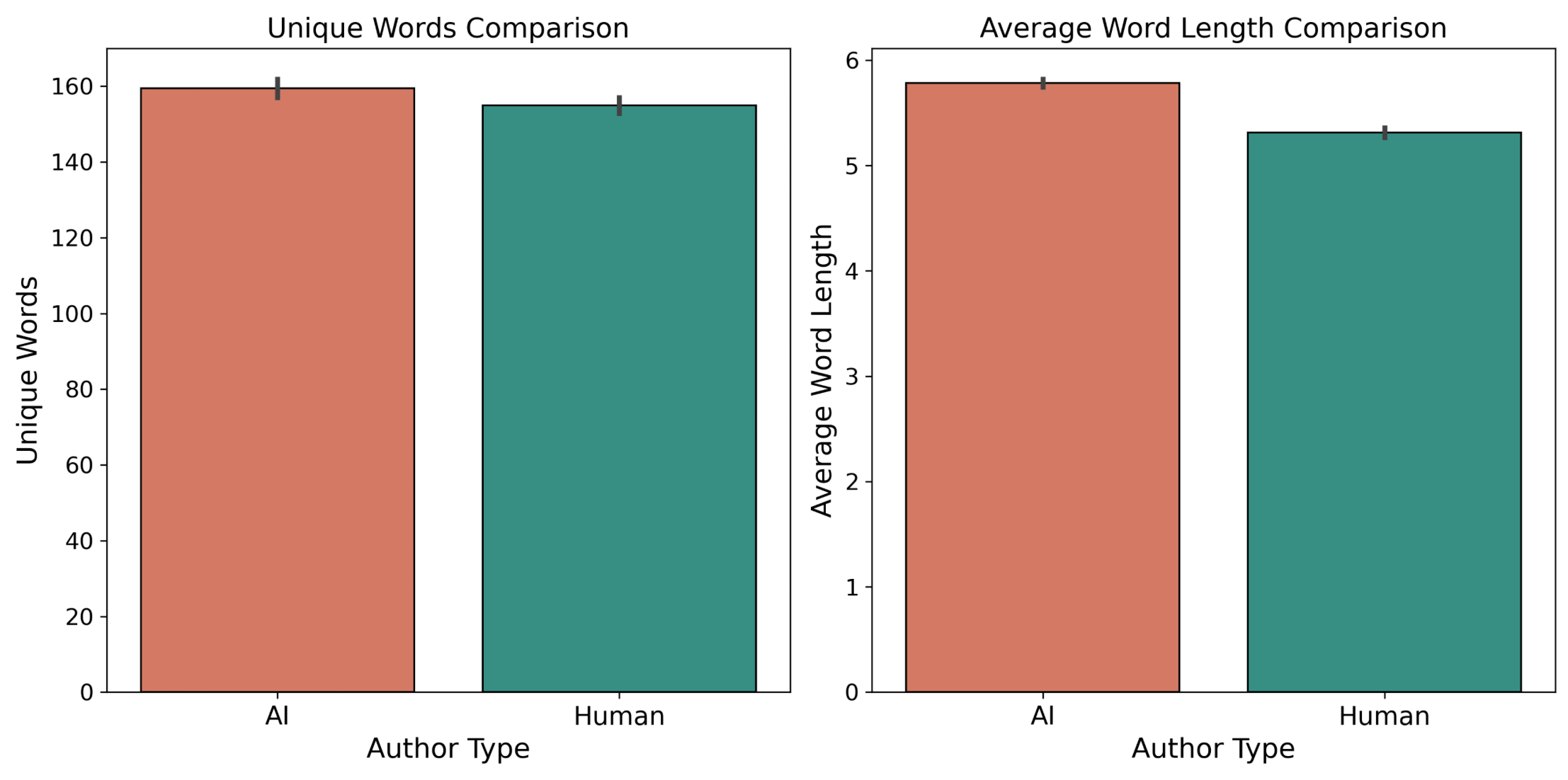
The graphs speak for themselves. AI submissions had a slightly more diverse vocabulary and tended to use slightly longer words. But the more interesting point is just how close the two author types were in both cases. LLMs have a tendency to hold up a mirror to us.
Wrapping up
Without a crystal ball, it’s hard to know the magnitude and timing of the major effects that AI will have on the global economy and on jobs. This paper offers a, semi-controlled, insight to where things are at as of March 2024. Looks like us humans still have the edge, for now!