
Do long context windows actually work?
The answer is, not as advertised

Context windows for LLMs are breaking seven figures (Gemini 2.5, Llama 4), but do these models perform as well with 1,000,000 tokens as they do with 1,000? If you’ve ever pushed LLMs with lots of context, even just a few hundred thousand tokens, you know that the answer is a resounding no.
We’re going to check out three resources, Fiction LiveBench, Databricks’ long-context RAG tests, and RULER (paper from NVIDIA). They all generally converge on the same point: most models start degrading somewhere between 16k and 64k tokens. Even the latest flagship models like o3-pro drop heavily in performance when you cross six figures.
In this post we’ll dig into the data that shows how LLM performance degrades as context windows grow, unpack why Needle-in-a-Haystack experiments are not a great benchmark for demonstrating an LLM’s ability to use its context window, and what you can do to overcome these limits.
1. Fiction LiveBench: Real-world long-form reading
Fiction LiveBench sends an LLM a portion of a story and then a specific question, all in one prompt (example below). This is very different from Needle-in-a-Haystack experiments in that it judges the comprehension of a model, versus a simple retrieval task.
Latest results
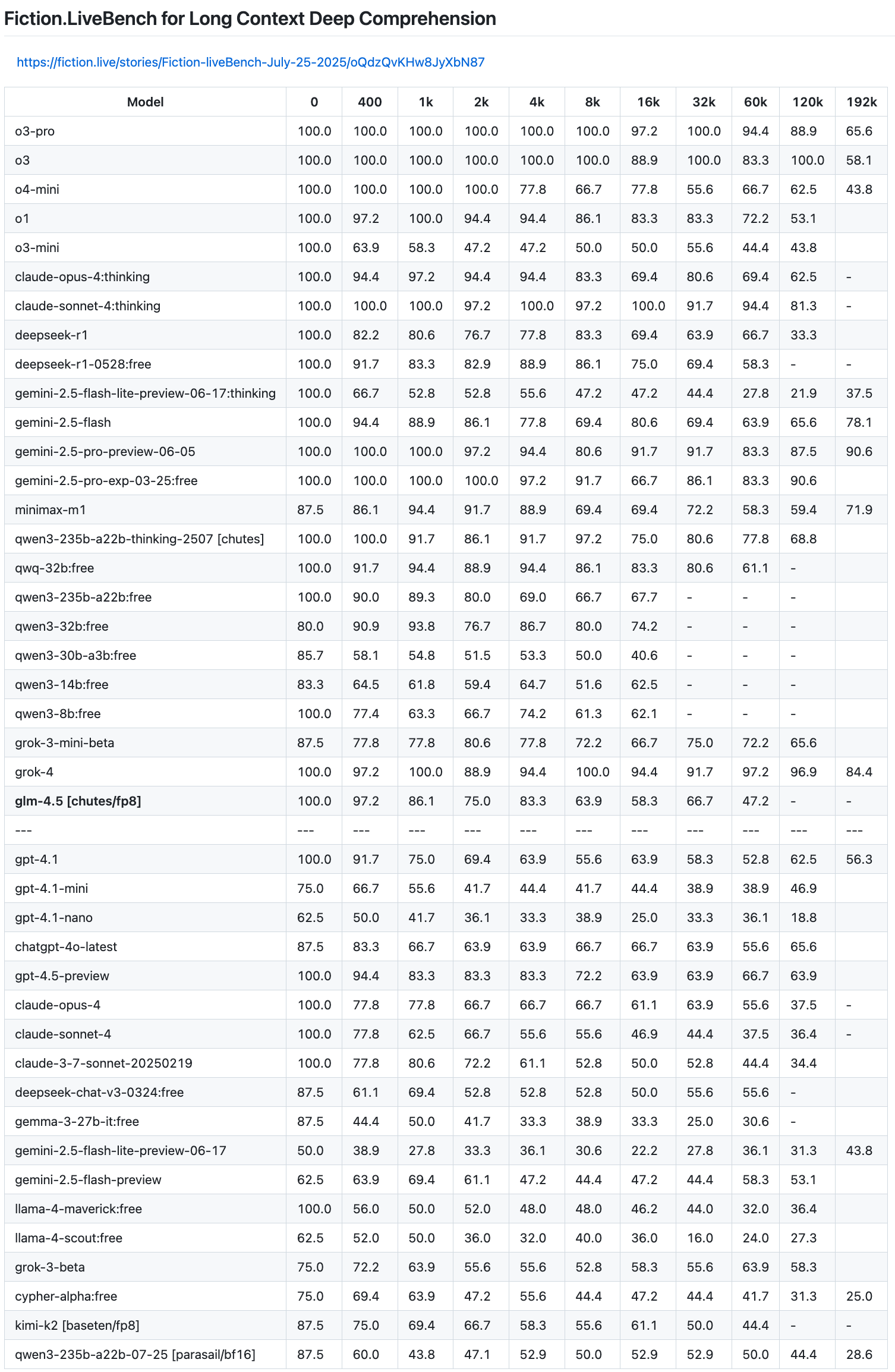
Grok 4 is the current SOTA, with Gemini 2.5 pro preview not too far behind
o3-pro is good up to 120k tokens, but drops off at 192k tokens
GPT-4.5-preview and GPT-4.1 are the best non-reasoning models.
Prompt example
I'm conducting a LLM comprehension test. I'm going to give you a story, and at the end you're going to answer a question about the story. Story:
---
The Shadow's Blade Prologue: The Fading Empire The year 2097 marked the thirtieth year of Imperial rule. What had begun as a corporate oligarchy consolidating power during the resource wars had evolved into a full-fledged authoritarian regime. The gleaming metropolises of New Shanghai, Neo-Angeles, and Upper Manhattan housed the elite in climate-controlled luxury, while the majority of humanity…STORY CONTINUE
---Question: Finish the sentence, what names would Jerome list? Give me a list of names only.
2. Databricks Long-Context RAG Experiments: When Recall Keeps Rising but Answers Slide
Databricks ran 2000+ RAG runs on 13 open-source and commercial models, feeding ever-larger piles of retrieved chunks (2k → 128k tokens) into each model and grading the answers with a calibrated GPT-4 judge.
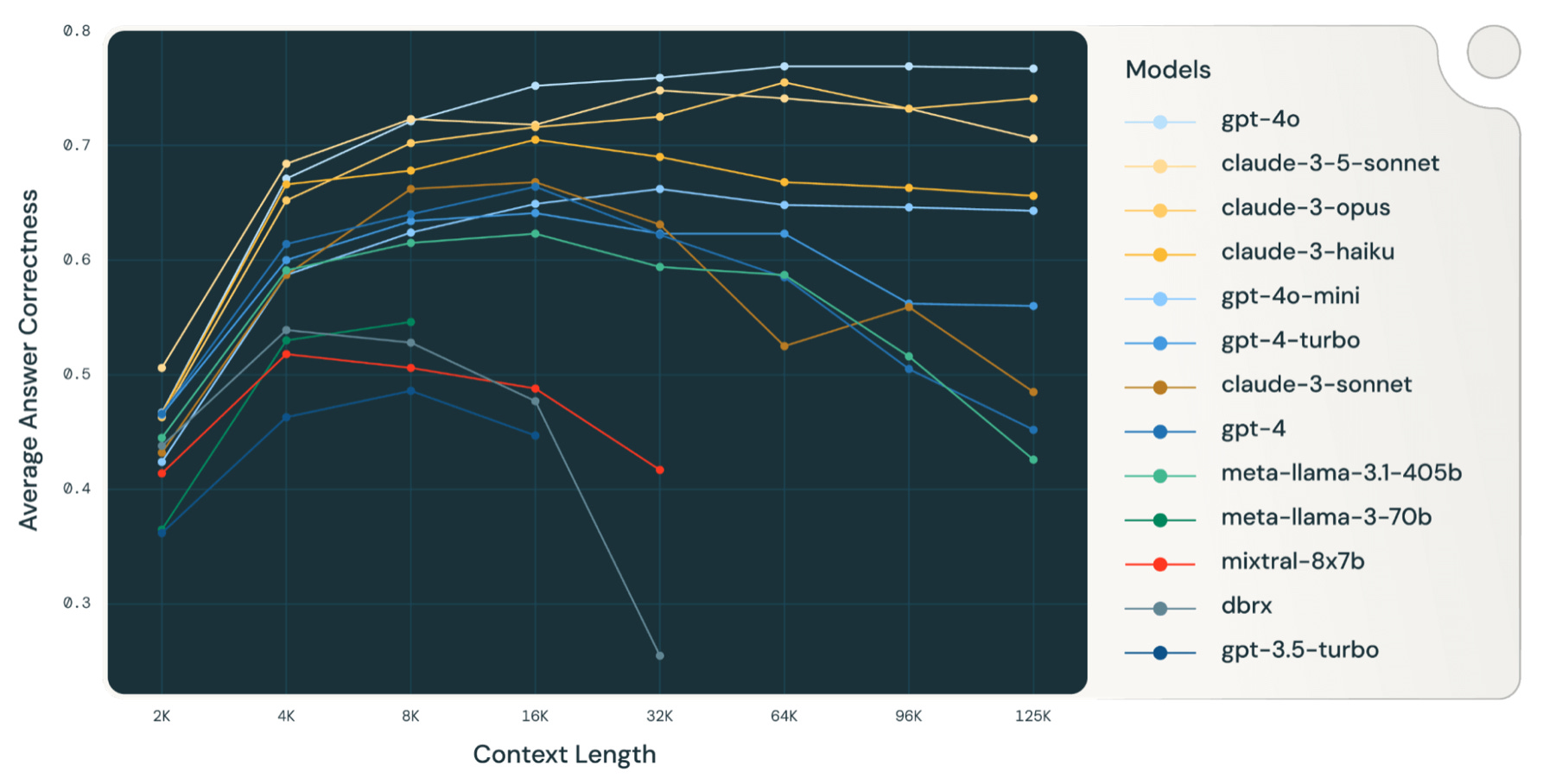
Sweet-spot ≈ 16k – 32k tokens. GPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 preview keep climbing to ~64k, but most models peak early, then decay.
Open-source fall first. Mixtral-8×7B, DBRX, and Llama 3.1-70B start sliding after 8k – 16k.
Failure modes
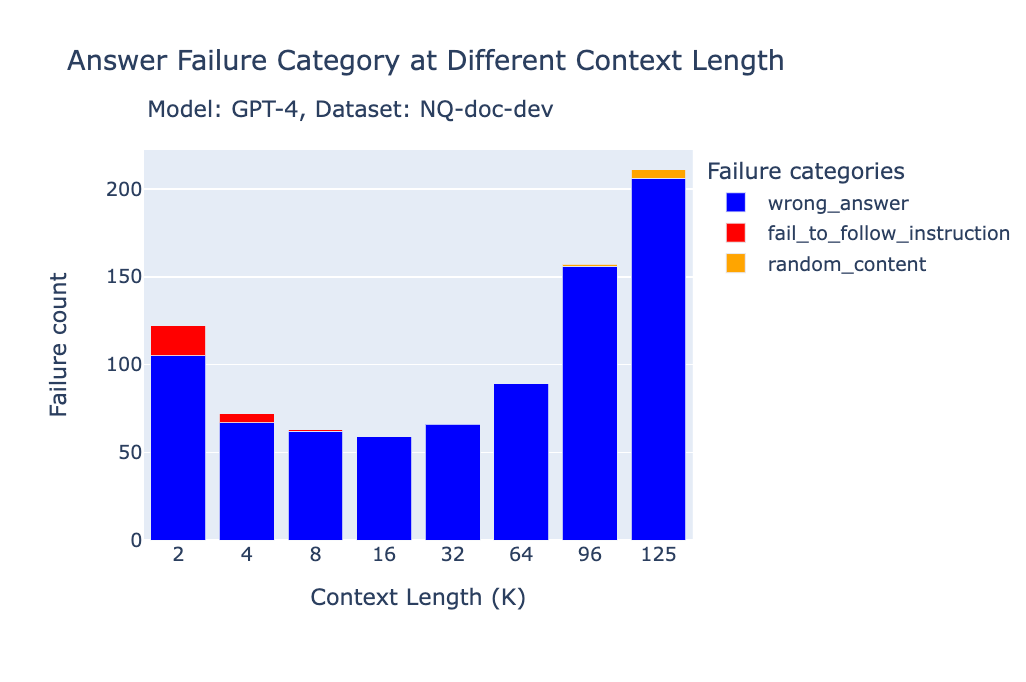
GPT-4 / GPT-4-Turbo
Failure flag → wrong answer (with occasional random content)
After ~32k tokens, GPT-4 still writes coherent prose but is more likely to get facts wrong.
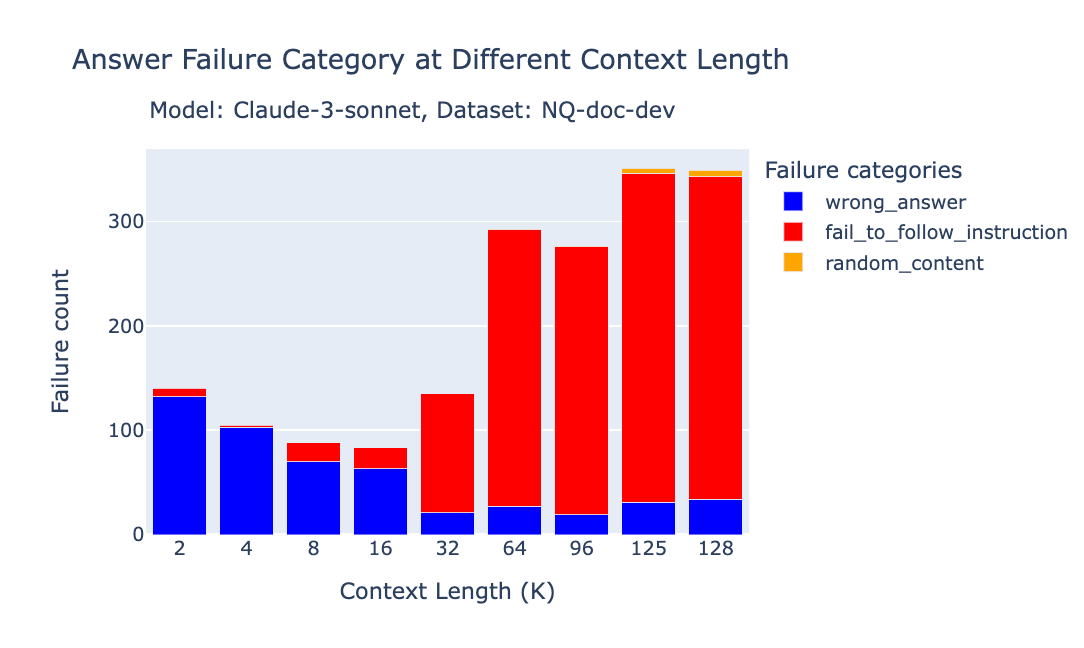
Claude 3 Sonnet
Failure flag → fail to follow instruction (copyright refusals)
Accuracy holds into the mid-teens, then safety filters start to trigger more often. Refusals climb from <4% at 16k to ~50% by 64k, replacing answers with “I’m afraid I can’t…” boilerplate. The more tokens, the more likely you are to trip policy triggers.
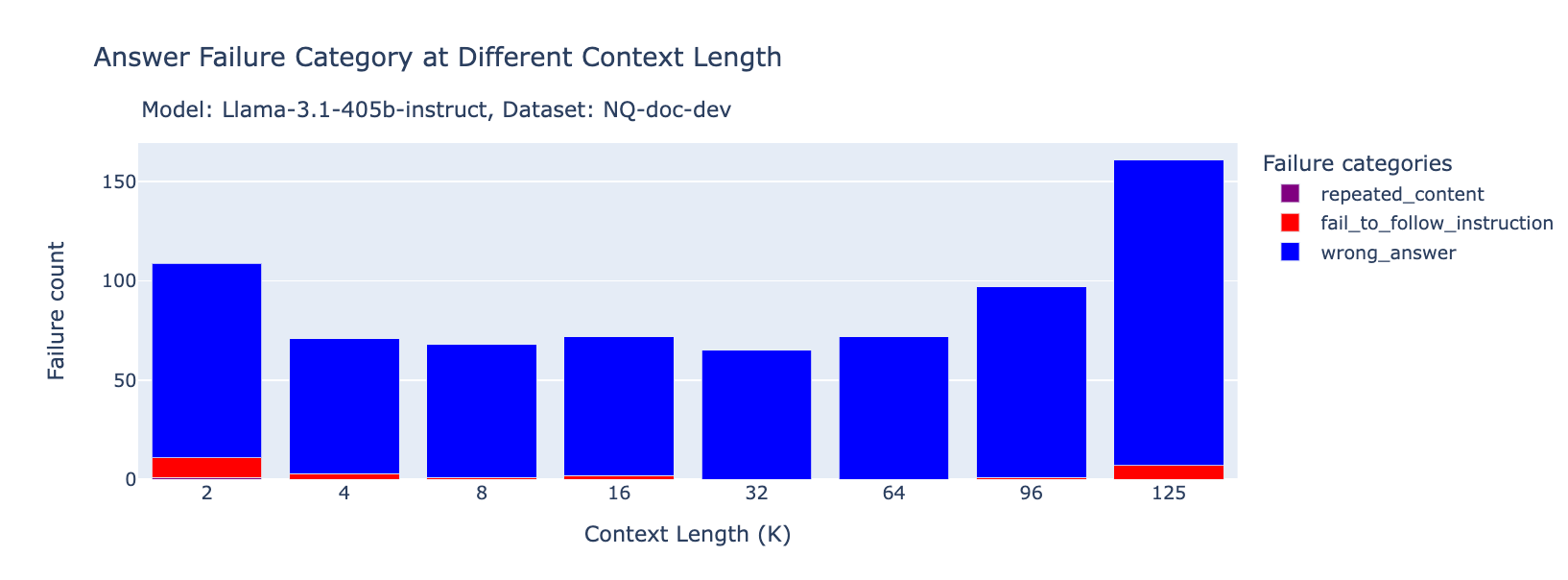
Llama-3.1-405B-Instruct
Failure flag → wrong answer
Similar to mirrors GPT-4, when Llama missteps, it is usually to get facts wrong.
3. RULER — Synthetic Stress-Tests that Push Past Simple Retrieval
RULER (NVIDIA, 2024), older paper, but still a good one, was built around a single question: “How much of a long context can a model actually reason over once the task gets harder than finding one exact string?”
To find out, the authors auto-generated 13 different types of tasks at varying lengths from 4k to 128k tokens, grouped into three broad families:
Needle-in-a-Haystack (NIAH)
Multi-hop Tracing: Follow an entity through a chain of references scattered across the prompt.
Aggregation: Collect and combine many small facts (e.g., “list the five most-frequent words”).
Results
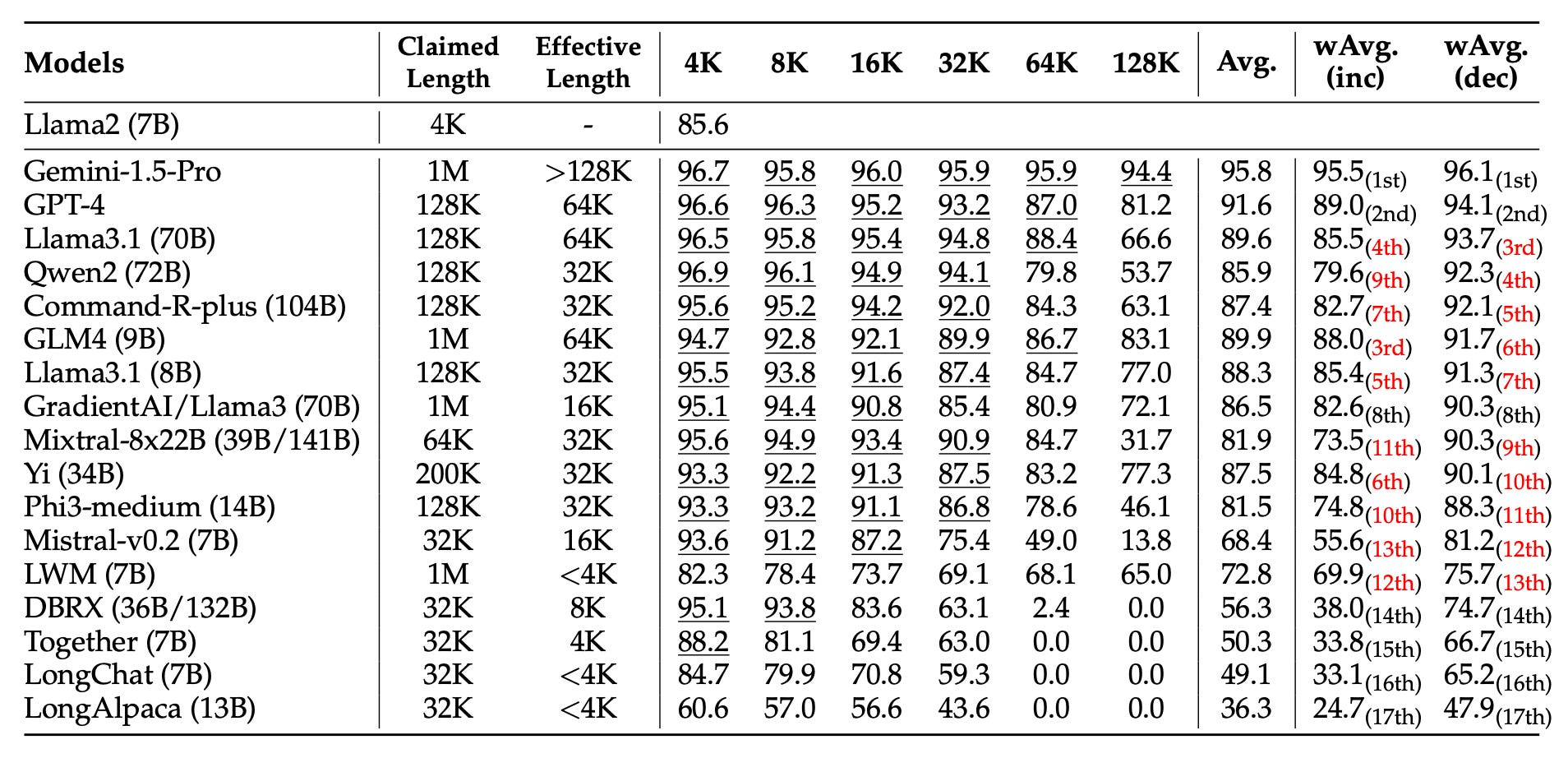
The authors set a baseline to compare performance to:
Llama-2-7B’s score of 85.6% at 4k tokens was the baseline that all the other models were compared to.
Underlined numbers in the table are scores that beat the 85.6% baseline.
The “Effective Length” column marks the furthest column to the right that is still underlined.
Example: GPT-4 stays above 85.6% through 64k, then drops to 81% at 128k, so its effective length is reported as 64k.
If a score isn’t underlined, the model has already fallen below baseline at that length.
Only Gemini 1.5 Pro stays “above baseline” all the way to 128k.
Conclusion
Having room for a million tokens doesn’t mean a model can understand a million tokens. Fiction LiveBench shows deep-comprehension accuracy sliding long before the max window, usually closer to 32k, with Grok 4 and Gemini being the two standouts above 192k tokens. In practice, assume a usable band of 16k-64k tokens for most models. Start your prompts in that range, and if you want to push it, do so in 10% increments and monitor performance.
Great job putting all this together — very helpful!