
China’s Open-Source Models Are Catching Up Faster Than Anyone Expected
US Startups are starting to actually use them in production....

A year ago, the model landscape felt predictable. It was mostly OpenAI vs. Anthropic, with Google, xAI, and Meta starting to gain some steam, everything else was an afterthought. Then, in January DeepSeek launched R1 and catapulted onto the scene, and I had my 2 seconds of fame being interviewed for the Wall Street Journal.

Even after that launch, if you were building an AI company and you wanted the best performance, you paid for a closed-source U.S. model. If you wanted something cheap or hackable, you reached for an open-source model and accepted the huge performance gap that came with it.
That gap has been closing over the last year.
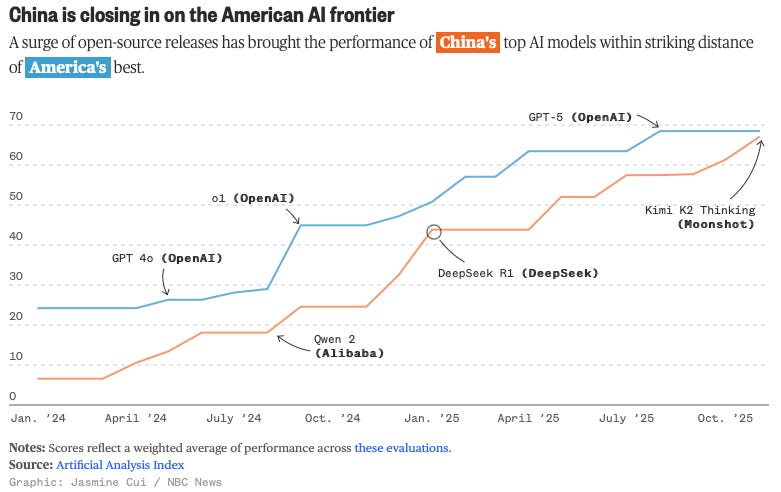
There are always interesting stories in the world of AI, but my favorite has been the rise of Chinese open-weights. These models are improving faster, getting cheaper, and closing the distance to the frontier at a rate that’s starting to make everyone a little uncomfy.
The best example of that shift is DeepSeek’s latest release.
DeepSeek V3.2: The Model Everyone’s Suddenly Paying Attention To
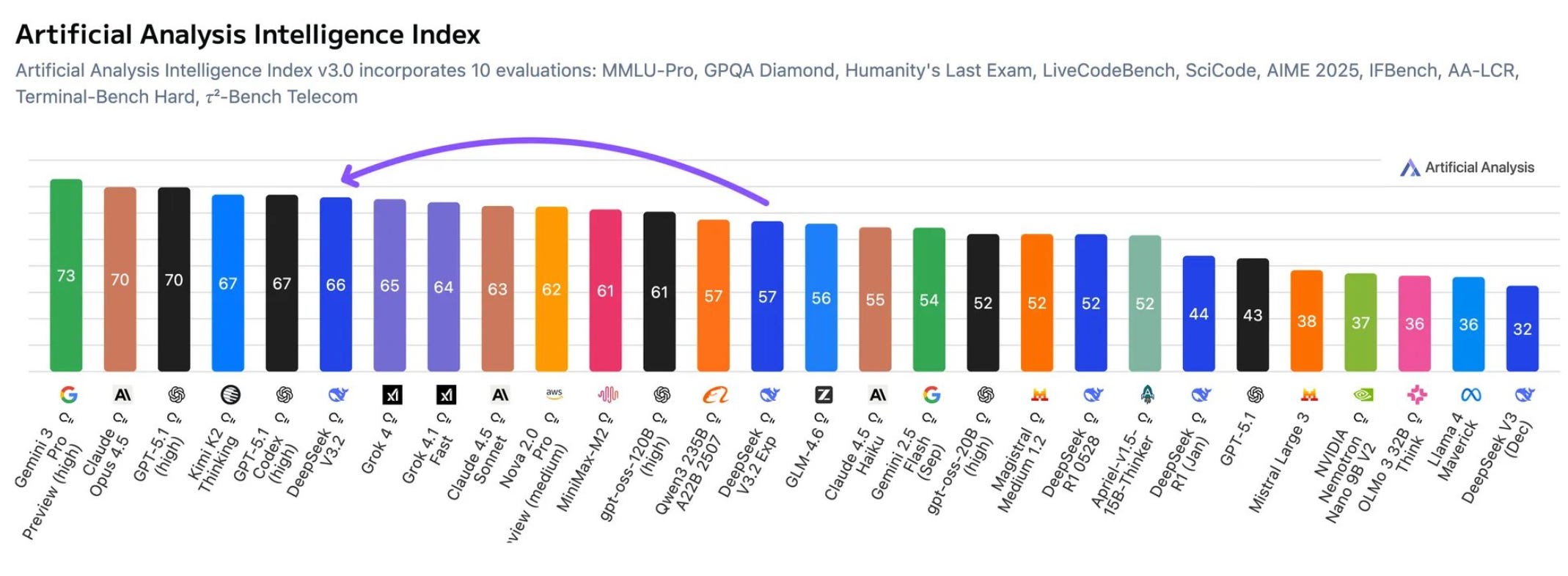
The DeepSeek V3.2 launch this week wasn’t as loud as the R1 release, but it’s still really important and continues the trend of kick-ass open-source models from China.
The model is open-weight, MIT-licensed, and, even when hosted by DeepSeek, costs only $0.28 / $0.42 per million input/output tokens, compared to $5 / $25 for Claude Opus 4.5 and $5 / $15 for Claude Sonnet 4.5. It’s able to be so inexpensive for a few reasons:
Mixture-of-Experts design → DeepSeek V3.2 has 671B total parameters, but uses only ~37B active parameters per token. For comparison, OpenAI and Anthropic models are dense, meaning every parameter is active for every token generated.
DeepSeek Sparse Attention (DSA) → Their custom attention mechanism cuts complexity from O(L²) to O(L × K) for long contexts, making inference much cheaper than what dense attention architectures pay at scale. I.e. costs shift from being exponential to linear.
Lower infrastructure & energy costs in China
Open weights → Price competitively with self-hosting
Strategic pricing → Capture adoption, who cares about margin
In the latest Artificial Analysis Intelligence Index, V3.2 scored a 66, leapfrogging models like Grok 4 and Claude 4.5 Sonnet(!) and putting it just behind Kimi K2 and the high-end GPT-5.1 and Gemini models.
To put that in perspective, in roughly a year:
DeepSeek’s models have gone from a score of 32 → 66
Google’s models have gone from a score of 32 → 63
Anthropic models have gone from 30-70
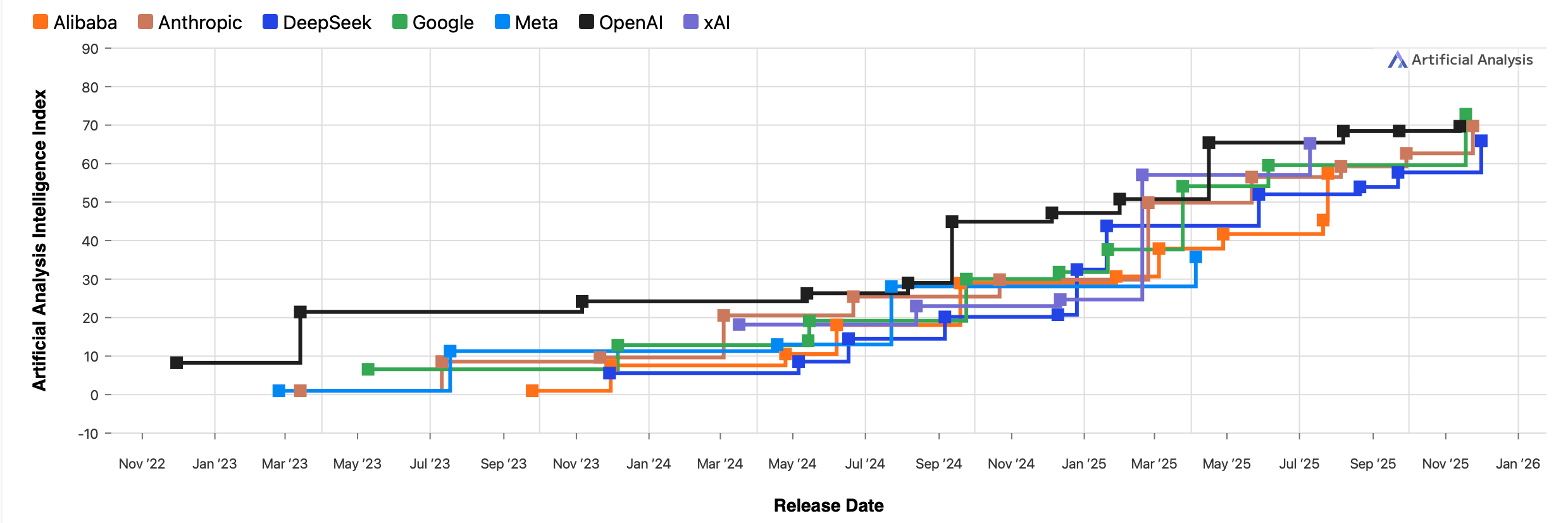
DeepSeek still isn’t quite on the level of the top 3 US AI companies, but it’s close.
One last point on the launch. Also included was a heavy reasoning model called, V3.2-Speciale. It wins or ties first place across several math and coding competitions (AIME, CMO, ICPC World Finals, IOI).
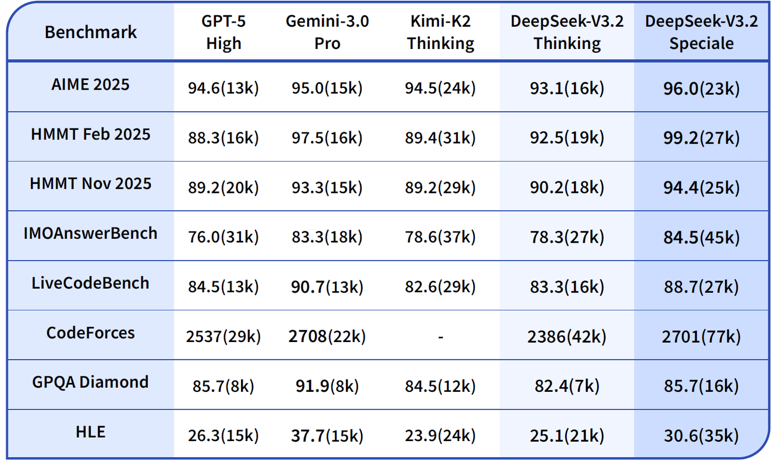
If you look on Artificial Analysis you’ll see that it scores lower on various benchmarks. That’s because the API endpoint currently doesn’t support tool use. When it does, it will likely be the highest-scoring open-weight model in existence.
So how close are open-source models from China to closed-source US models?
Time for some charts, thanks to Artificial Analysis.
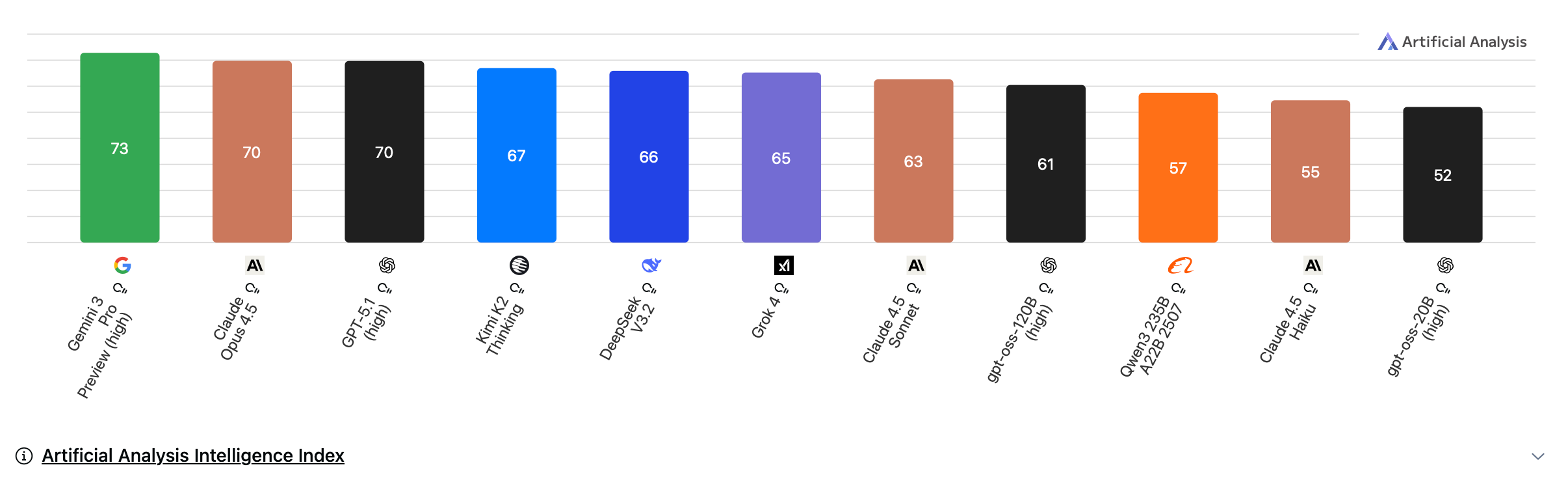
1. Chinese open-weights are now competitive with U.S. frontier models on intelligence.
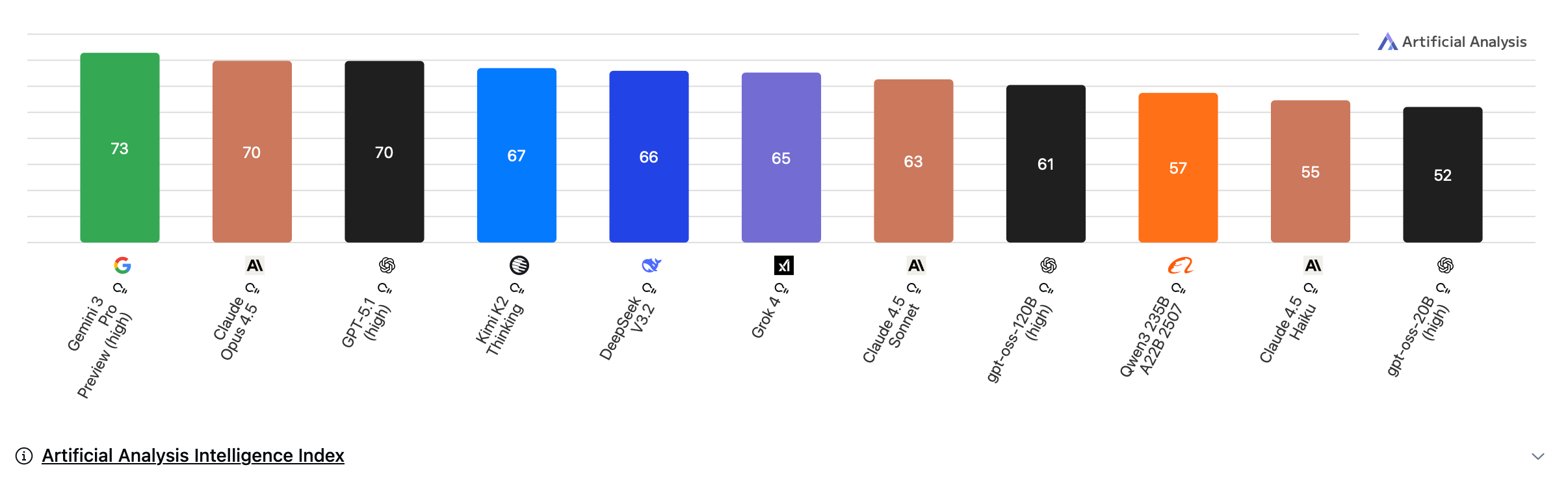
Notably, the top three models are all from US companies, and the difference between even a 70 on this benchmark (GPT-5.1) and a 66 (DeepSeek V3.2) is substantial.
But, important to note that two open source models, Kimi K2 Thinking and DeepSeek V3.2 currently beat Sonnet 4.5 thinking.
2. On par with token efficiency of US models
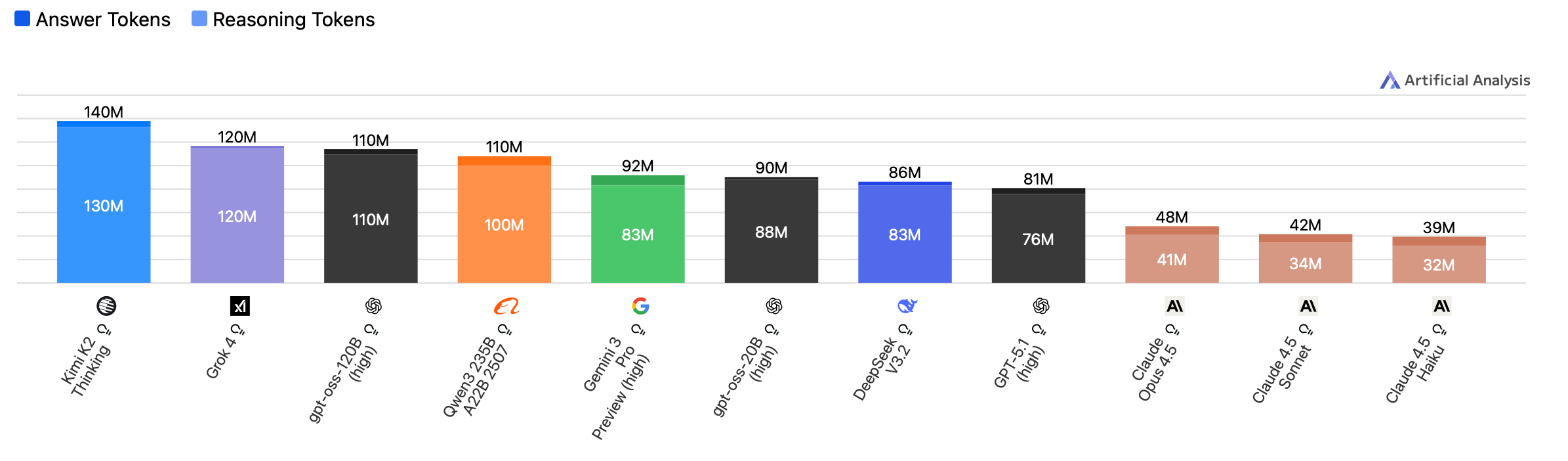
Both the US and China have a few outliers (Kimi K2 and Grok 4)
DeepSeek V3.2 is in line with GPT-5.1 and Gemini 3
3. Economically, it’s not even close.
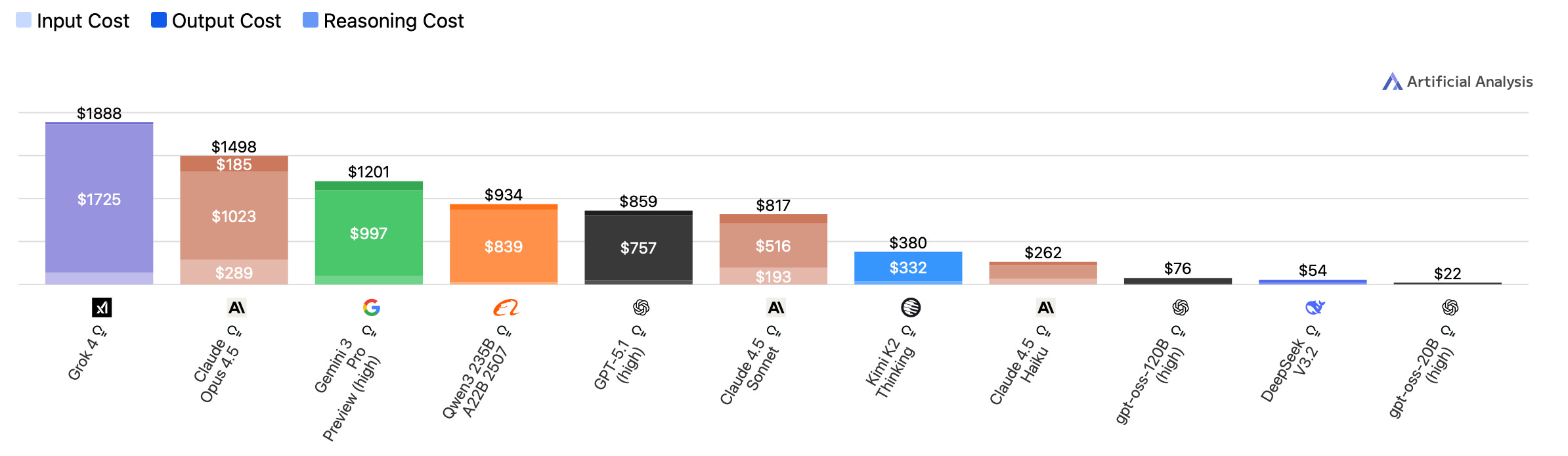
Running the full benchmark suite costs:
Grok 4: $1,888 (35x more expensive than DeepSeek)
Opus 4.5: $1,498 (28x)
Gemini 3 Pro Preview: $1,201 (22x)
GPT-5.1 (high): $859 (16×)
DeepSeek V3.2: $54
4. Intelligence vs. Cost breakdown
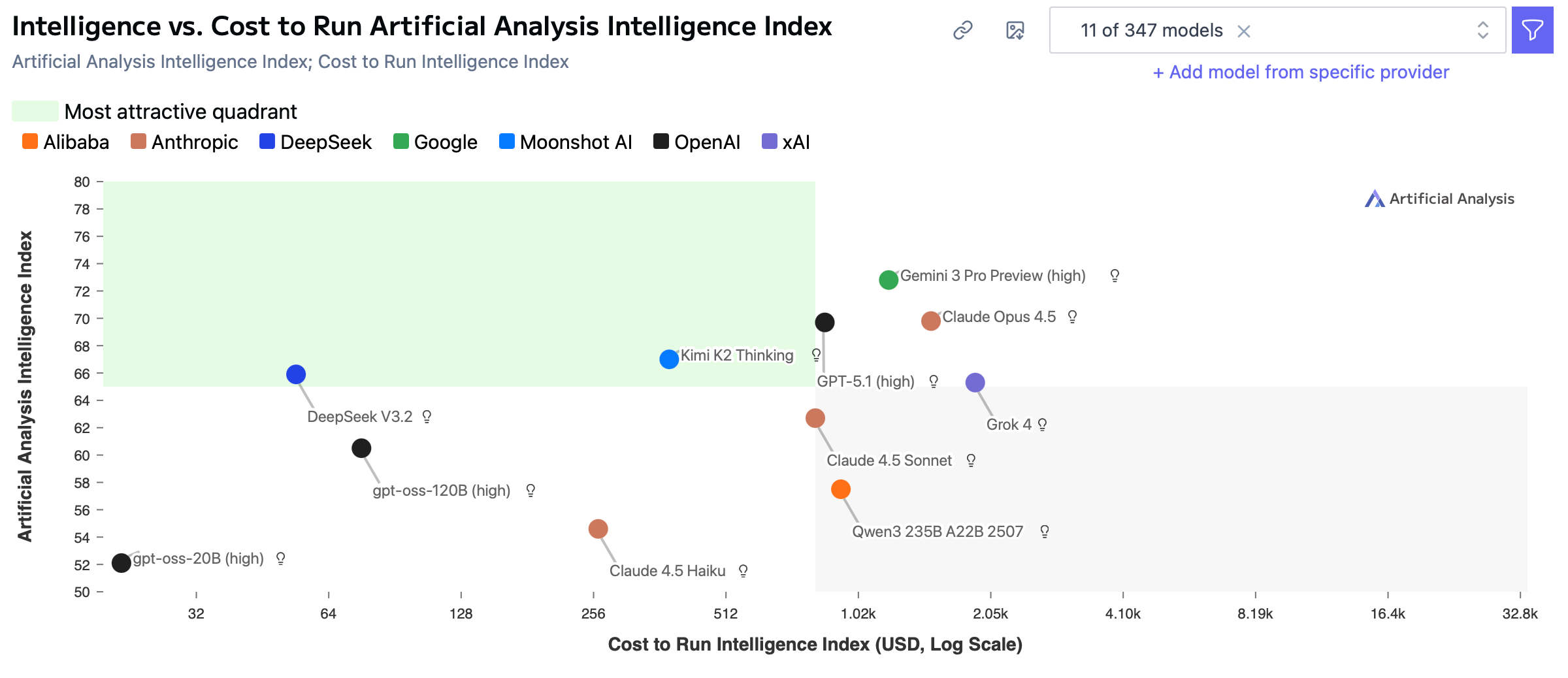
If you map intelligence vs. cost on a log scale, DeepSeek and Kimi K2 sit alone in the top-left corner (high IQ, low cost). U.S. frontier models occupy the top-right corner:
high IQ, higher cost.
Why this matters
More and more companies are either using or exploring Chinese, open-source models for their applications. Cursor’s Composer model is rumored to be a Qwen model.

It’s one thing for a cheap model to get “pretty good.”
It’s another for a cheap, open model to get this good while U.S. models get more expensive (consuming more tokens).
Closed-source U.S. models still hold the absolute frontier:
Opus 4.5 is the best coding model
Gemini 3 Pro holds the top overall intelligence score
GPT-5.1 remains extremely reliable and broadly capable.
But the economic frontier, the one that determines what developers actually deploy, is now more competitive than ever.
Compelling analysis of the speed at which Chinese open-source models are closing the intelligence gap while dramatically undercutting on cost. The mixture-of-experts architecture combined with DeepSeek Sparse Attention creating that 16-28x cost advantage is particularly notewothy, especially when paired with performance scores now exceeding Sonnet 4.5. Your observation about the economic frontier mattering more than the absolute frontier for actual deployemnt decisions captures something critical that benchmarks alone miss. The Cursor/Qwen connection you mentioned earliersugests this shift is already happening quietly in production systems.