


Apple thinks thinking models don't think
Plus, check out these prompts from the GitHub Copilot team

Apple’s latest paper, The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity, is one of the harsher critiques of reasoning models out there.
Instead of the usual benchmarks, the researchers used four fresh logic puzzles to run tests between non-reasoning and reasoning models. The findings were more than surprising. In particular, the last graph mentioned below (almost an afterthought in the paper) turned out to be the most revealing. Let’s dive in.
For those that prefer video:
The four tests

Tower of Hanoi
Checker Jumping
River Crossing
Blocks World
These puzzles were picked because they:
Let researchers dial difficulty up or down
Rarely overlap with model training data
Have clear algorithmic solutions for ground-truth scoring
The Big Picture
The experiments ran across the four puzzles and scaled up in complexity. The results paint a three-zone picture.
Low Complexity (yellow) – Non-reasoning models edge out reasoning models
Medium Complexity (blue) – reasoning models pull ahead.
High Complexity (red) – accuracy for both model types falls to ~0. The cliff is real.

The Thinking Cliff
The researchers also tracked how the # of thinking tokens scaled with complexity (bottom row of graphs).
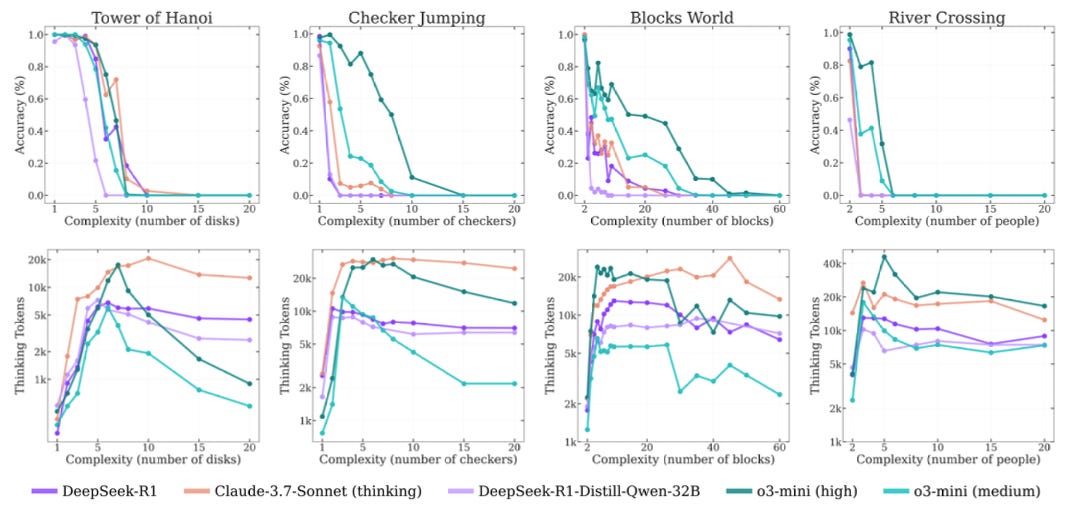
Easy puzzles: Thinking tokens climb quickly. Short CoT boosts accuracy without heavy token spend.
Mid-range: Token counts plateau at the same point accuracy peaks.
Crossing the Thinking Cliff: Tokens and accuracy plunge at very similar levels of complexity. It is almost like the model “gives up” when the level of complexity hits some threshold.
Given the solution, no performance increase
Okay, on to my favorite part. In one of the last experiments, the researchers included the algorithm needed to solve the Tower of Hanoi puzzle. The results speak for themselves.
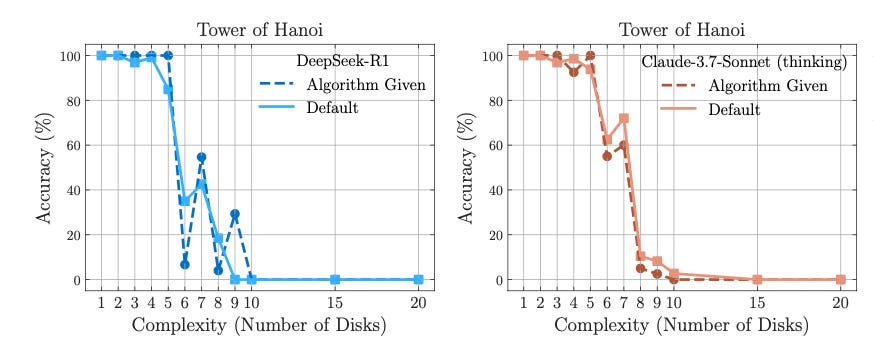
Basically ZERO improvement in performance, and failure still happens at the same level of complexity. Translation: models struggle with executing logical steps, not just planning them.
What This Means for Builders
Match model to task complexity. You don’t always need a huge reasoning model.
Watch for the cliff. If accuracy collapses past a certain depth, more tokens might not be able to save you.
Prompt engineering is critical. You would think having the answer key in your prompt would help the model, but as we saw with the last experiment, that isn’t the case. Iterate on prompts → write evals → test → repeat.
Prompt(s) of the week
We just launched a collection of prompts in partnership with GitHub in PromptHub. You can open the prompts directly into Copilot to test! It’s pretty fun, and a nice first step for our collaboration with GitHub.
I would suggest to enhance this article with the other paper “The Illusion of the Illusion of Thinking A Comment on Shojaee et al. (2025)”